Contents
- Intro
- RStudio
- Basic principles of
Rprogramming - Putting it all together
- Functions
- Making the computer do the heavy lifting
- Reshaping Data
- Data visualisation
- Useful tips
- Jargon dictionary
Intro
The first contact with R might feel a little overwhelming, especially if you haven’t done any programming before.
Some things are fairly easy to understand but others do not come naturally to people.
To help you with the latter group, here are some tips on how to approach talking to computers.
Jargon warning
It is unavoidable to include some technical language. At first, this may feel a little obscure but the vocab needed to understand this document is not large. Besides, learning the jargon will make it possible for you to put into words what it is you need to do and, if you’re struggling, ask for help in places such as Stack Overflow.
If you come across an unfamiliar term, feel free to consult the dictionary at the bottom of this document.
We’re smarter than them (for now)
Talking to a computer is can sometimes feel a little difficult. They are highly proficient at formal languages: they understands the vocab, grammar, and syntax perfectly well. They can do many complex things you ask them to do, so long as you are formal, logical, precise, and unambiguous. If you are not, they won’t be able to help you or worse, will do something wrong. When it comes to pragmatics, they are lost: they doesn’t understand context, metaphor, shorthand, or sarcasm. The truth is that they just aren’t all that smart so they need to be told what to do in a unambiguous way.
Keep this in mind whenever you’re working with R.
Don’t take anything for granted, don’t rely on R to make any assumptions about what you are telling it.
Certainly don’t try to be funny and expect R to appreciate it!
It takes a little practice to get into the habit of translating what you want to do into the dry, formal language of logic and algorithms but, on the flip side, once you get the knack of it, there will never be any misunderstanding on the part of the machine.
With people, there will always be miscommunication, no matter how clear you try to be, because people are very sensitive to context, paralinguistic and non-verbal cues, and the pragmatics of a language.
Computers don’t care about any of that and thus, if they’re not doing what you want them to, the problem is in the sender, not the receiver.1 That is exactly why they’re built like that!
Instead of thinking about computers as scary, abstruse, or boring, learn to appreciate this quality of precision as beautiful. That way, you’ll get much more enjoyment out of working with them.
Think algorithmically
By algorithmically, we mean in a precise step-by-step fashion where each action is equivalent to the smallest possible increment.
So, if you want a machine to make you a cup of tea, instead of saying: “Oi R! Fetch me a cuppa!”, you need to break everything down.
Something like this:
Go to kitchenIf no kitchen, jump to 53Else get kettleIf no kettle, jump to 53Check how much water in kettleIf is more or equal than 500 ml of water in kettle, jump to 15Place kettle under cold tapOpen kettle lidTurn cold tap onCheck how much water in kettleIf there is more than 500 ml of water in kettle, jump to 13Jump to 10Turn cold tap offClose kettle lidIf kettle is on base, jump to 17Place kettle on baseIf base is plugged in mains, jump to 19Plug base in mainsTurn kettle onGet cupIf no cup, jump to 53Get tea bag# yeah, we’re not poshIf no tea bag, jump to 53Put tea bag in cupIf kettle has boiled, jump to 27Jump to 25Start pouring water from kettle to cupCheck how much water in cupIf there is more than 225 ml of water in cup, jump to 31Jump to 28Stop pouring water from kettleReturn kettle on baseWait 4 minutesRemove tea bag from cupPlace tea bag by edge of sink# this is obviously your partner’s/flatmate’s programOpen fridgeSearch fridgeIf full fat milk is not in fridge, jump to 41Get full fat milk# full fat should be any sensible person’s top choice. True fact!Jump to 43If semi-skimmed milk is not in fridge, jump to 51# skimmed is not even an option!Get semi-skimmed milkTake lid of milkStart pouring milk in cupCheck how much liquid in cupIf more or equal to 250 ml liquid in cup, jump to 48Jump to 45Stop pouring milkPut lid on milkReturn milk to fridgeClose fridge# yes, we kept it open! Fewer steps (I’m not lazy, I’m optimised!)Bring cup# no need to stirEND
so there you go, a nice cuppa in 53 easy steps!
Obviously, this is not real code but something called pseudocode: a program-like set of instructions expressed in a more-or-less natural language. Surely, we could get even more detailed, e.g., by specifying what kind of tea we want, but 53 steps is plenty. Notice, however, that, just like in actual code, the entire process is expressed in a sequential manner. This sometimes means that you need to think about how to say things that would be very easy to communicate to a person (e.g., “Wait till the kettle boils”) in terms of well-defined repeatable steps. In our example, this is done with a loop:
If kettle has boiled, jump to 27Jump to 25Start pouring water from kettle to cup
The program will check if the kettle has boiled and, if it has, it will start pouring water into the cup. If it hasn’t boiled, it will jump back to 25. and check again if it has boiled. This is equivalent to saying “wait till the kettle boils”.
Note that in actual R code, certain expressions, such as jump to (or, more frequently in some older programming languages goto) are not used so you would have to find other ways around the problem, were you to write a tea-making program in R.
However, this example illustrates the sort of thinking mode you need to get into when talking to computers.
Especially when it comes to data processing, no matter what it is you want your computer to do, you need to be able to convey it in a sequence of simple steps.
Don’t be scared
It is quite normal to be a little over-cautious when you first start working with a programming language.
Rest assured that, when it comes to R, there is very little chance you’ll break your computer or damage your data, unless you set out to do so and know what you’re doing.
When you read in your data, R will copy it to the computer’s memory and only work with this copy.
The original data file will remain untouched.
So please, be adventurous, try things out, experiment, break thingst’s the best way to learn programming and understand the principles and the logic behind the code.
RStudio
RStudio is what is called an Integrated Development Environment for R.
It is dependent on R but separate from it.
There are several ways of using R but RStudio is arguably the most popular and convenient.
Let’s have a look at it.
The “heart of R” is the Console window.
This is where instructions are sent to R, and its responses are given.
The console is, almost exclusively, the way of talking to R in RStudio.
The Information area (all of the right-hand side of RStudio) shows you useful information about the state of your project.
At the moment, you can see some relevant files in the bottom pane, and an empty “Global Environment” at the top.
The global environment is a virtual storage of all objects you create in R.
So, for example, if you read in some data into R, this is where they will be put and where R will look for them if you tell it to manipulate or analyse the data.
Finally, the Editor is where you write more complicated scripts without having to run each command.
Each script, when saved, is just a text file with some added bells and whistles.
There’s nothing special about it.
Indeed, if you wanted to, you could write your script in any plain text editor, save it, change its extension from .txt to .R and open it in RStudio.
There is no need to do this but you could.
When you run such a script file, it gets interpreted by R in a line by line fashion.
This means that your data cleaning, processing, visualisation, and analysis needs to be written up in sequence otherwise R won’t be able to make sense of your script.
Since the script is basically a plain text file (with some nice colours added by RStudio to improve readability), the commands you type in can be edited, added, or deleted just like if you were writing an ordinary document.
You can run them again later, or build up complex commands and functions over several lines of text.
There is an important practical distinction between the Console and the Editor: In the Console, the Enter key runs the command. In the Editor, it just adds a new line. The purpose of this is to facilitate writing scripts without running each line of code. It also enables you to break down your commands over multiple lines so that you don’t end up with a line that’s hundreds of characters long. For example:
The hash (#) marks everything to the right of it as comment.
Comments are useful for annotating the code so that you can remember what it means when you return to your code months later (it will happen!).
It also improves code readability if you’re working on a script in collaboration with others.
Comments should be clear but also concise.
There is no point in paragraphs of verbose commentary.
Writing (and saving) scripts has just too many advantages over coding in the console to list and it it is crucial that you learn how to do it. It will enable you to write reproducible code you can rerun whenever needed, reuse chunks of code you created for a previous project in your analysis, and, when you realise you made a mistake somewhere (when, not if, because this too will happen!), you’ll be able to edit the code and recreate your analysis in a small fraction of the time it would take you to analyse your data anew without a script. This way, if you write a command and it doesn’t do exactly what you wanted to do, you can quickly tweak it in the editor and run it again. Also, if you accidentally modify and object and mess everything up, you can just re-run your entire script up to that point and pretend nothing ever happened. Or different still, let’s say you analysed your data and wrote your report and then you realised you made a mistake, for instance forgot to exclude data you should have excluded or excluded some you shouldn’t have. Without a “paper-trail” of your analysis, this is a very unpleasant (but, sadly, not unheard of) experience. But with a saved analysis script, you can just insert an additional piece of code in the file, re-run it and laugh it off. Or do the first two, and then take a long hard look at yourselfhatever the case, using the script editor is just very, very useful!
However, the aim is to keep the script tidy.
You don’t need to put every single line of code you ever run into it.
Sometimes, you just want to look at your data, using, for example View(df).
This kind of command really doesn’t need to be in your script.
As a general rule of thumb, use the editor for code that adds something of value to the sequence of the script (data cleaning, analysis, code generating plots, tables, etc.) and the console for one-off commands (when you want to just check something).
Here is an example of what a neat script looks like (part of the Reproducibility Project: Psychology analysis2). Compare it to your own scripts and try to find ways of improving your coding.
For useful “good practice” guidance on how to write legible code, see the Google style guide.
Basic principles of R programming
The devil’s in the detail
It takes a little practice to develop good coding habits.
As a result, you will likely get a lot of errors when you first try to do things in R.
That’s perfectly normal and the following the tips below will make it a lot better rather quickly.
Promise!
When you do encounter an error or when R does something other than what you wanted, it means that, somewhere along the way, there has been a mistake in at least one of the main components of the R language:
Vocabulary
Simply put, you used the wrong word and so R understood something other than what you intended.
Translated into a more programming language, you used the incorrect function to perform some operation or performed the right operation on the wrong input.
Maybe you wanted to calculate the median of a variable but instead, you calculated the mean.
Or maybe you calculated the median as you wanted but of the wrong variable.
Different still, you might have used the right function an the right object but R does not know the function because you haven’t made it accessible (more on this in the section on packages.
The former case is usually a matter of knowing the names of your functions, which comes with time.
The latter two are more of a matter of attention to detail.
Grammar
Grammatical mistakes basically consist of using the right vocabulary but using it wrong. This can be prevented by learning how to use the commands you want to use or at least knowing how to find out about them. For a more in-depth discussion, see the section on functions.
Syntax
The third pitfall consists in using the right words in the right way but stringing them together wrong.
Since programming languages are formal, things like order and placement of commas and brackets matter a great deal.
This is usually the source of most of the frustration caused by people’s early experience with R.
To avoid running into syntactic problems, try to always follow these principles:
- Every open bracket (
(,[,{) has to be closed at some point.()s are exclusively for functions.[]s are only for subsetting.{}s group together code we want to evaluate conditionally or iteratively or for writing your own functions.
- Commas are functional and have their place.
They are used to separate arguments in functions and dimensions in subsetting.
As such, they can only be used inside
()s and[]s. - White spaces are optional.
You are free (and indeed encouraged) to use them but, if you do, bear in mind they must not be inserted inside a name of a variable or function.
- For instance, there is a function called
as.numeric. There may not be a white space anywhere within this name.
- For instance, there is a function called
- Any unquoted (not surrounded by
's or"s) string of letters is interpreted as a name of some variable, dataset, or function. Conversely, any quoted string is interpreted literally as a meaningless string of characters.meanis a name of the function that computes the arithmetic mean (e.g.,mean(c(1, 3, 4, 8, 100))gives the mean of the numbers 1, 3, 4, 8, and 100) but"mean"is just a string of letters and performs no function inR.
Ris case sensitive –ais not the same asA.
Naturally, these guidelines won’t mean all that much to you if you are completely new to programming. That’s OK. Come back to them once you’ve finished reading this document. They will appear much more useful then.
If you want to keep it, put it in a box
Everything in life is merely transient; we ourselves are pretty ephemeral beings. (#sodeepbro)
However, R takes this quality and runs with it.
If you ask R to perform any operation, it will spew it out into the console and immediately forget it ever happened.
Let’s show you what that means:
# create an object (variable) a and assign it the value of 1
a <- 1
# increment a by 1
a + 1
[1] 2# OK, now see what the value of a is
a
[1] 1
So, R as if forgot we asked it to do a + 1 and didn’t change its value.
The only way to keep this new value is to put it in an object.
b <- a + 1
# now let's see
b
[1] 2
Think of objects as boxes.
The names of the objects are only labels.
Just like with boxes, it is convenient to label boxes in a way that is indicative of their contents, but the label itself does not determine the content.
Sure, you can create an R object called one and store the value of 2 in it, if you wish.
But you might want to think about whether or not it is a helpful name.
And what kind of person that makes you…
Objects can contain anything at all: values, vectors, matrices, data, graphs, tables, even code.
In fact, every time you call a function, e.g., mean(), you are running the code that’s inside the object mean with whatever values you pass to the arguments of the function.
Let’s demonstrate this last point:
# let's create a vector of numbers the mean of which we want to calculate
vec <- c(103, 1, 1, 6, 3, 43, 2, 23, 7, 1)
# see what's inside
vec
[1] 103 1 1 6 3 43 2 23 7 1# let's get the mean
# mean is the sum of all values divided by the number of values
sum(vec)/length(vec)
[1] 19# good, now let's create a function that calculates
# the mean of whatever we ask it to
function(x) {sum(x)/length(x)}
function(x) {sum(x)/length(x)}# but as we discussed above, R immediately forgot about the function
# so we need to store it in a box (object) to keep it for later!
calc.mean <- function(x) {sum(x)/length(x)}
# OK, all ready now
calc.mean(x = vec)
[1] 19# the code inside the object calc.mean is reusable
calc.mean(x = c(3, 5, 53, 111))
[1] 43# to show that calc.mean is just an object with some code in it,
# you can look inside, just like with any other object
calc.mean
function(x) {sum(x)/length(x)}
<bytecode: 0x0000000019992618>
Let this be your mantra: “If I want to keep it for later, I need to put it in an object so that is doesn’t go off.”
You can’t really change an object
Unlike in the physical world, objects in R cannot truly change.
The reason is that, sticking to our analogy, these objects are kind of like boxes.
You can put stuff in, take stuff out and that’s pretty much it.
However, unlike boxes, when you take stuff out of objects, you only take out a copy of its contents.
The original contents of the box remain intact.
Of course you can do whatever you want (within limits) to the stuff once you’ve taken it out of the box but you are only modifying the copy.
And unless you put that modified stuff into a box, R will forget about it as soon as it’s done with it.
Now, as you probably know, you can call the boxes whatever you want (again, within certain limits).
What might not have occurred to you though, is that you can call the new box the same as the old one.
When that happens, R basically takes the label off the old box, pastes it on the new one and burns the old box.
So even though some operations in R may look like they change objects, under the hood R copies their content, modifies it, stores the result in a different object puts the same label on it and discards the original object.
Understanding this mechanism will make things much easier!
Putting the above into practice, this is how you “change” an R object:
# put 1 into an object (box) called a
a <- 1
# copy the content of a, add 1 to it and store it in an object b
b <- a + 1
# copy what's inside b and put it in a new object called a
# discarding the old object a
a <- b
# now see what's inside of a
# (by copying its content and pasting it in the console)
a
[1] 2
Of course, you can just cut out the middleman (object b).
So to increment a by another 1, we can do:
a <- a + 1
a
[1] 3
It’s elementary, my dear Watson
When it comes to data, every vector, matrix, list, data frame - in other words, every structure - is composed of elements.
An element is a single number, boolean (TRUE/FALSE), or a character string (anything in “quotes”).
Elements come in several classes:
"numeric", as the name suggests, a numeric element is a single number: 1, 2, -725, 3.14159265, etc.. A numeric element is never in ‘single’ or “double” quotesumbers are cool because you can do a lot of maths (and stats!) with them."character", a string of characters, no matter how long. It can be a single letter,'g', but it can equally well be a sentence,“Elen síla lumenn’ omentielvo.”(if you want the string to contain any single quotes, use double quotes to surround the string with and vice versa). Notice that character strings inRare always in ‘single’ or “double” quotes. Conversely anything in quotes is a character string:It stands to reason that you can’t do any maths with cahracter strings, not even if it’s a number that’s inside the quotes!
"3" + "2"Error in "3" + "2": non-numeric argument to binary operator"logical", a logical element can take one of two values,TRUEorFALSE. Logicals are usually the output of logical operations (anything that can be phrased as a yes/no question, e.g., is x equal to y?). In formal logic,TRUEis represented as 1 andFALSEas 0. This is also the case inR:# recall that c() is used to bind elements into a vector # (that's just a fancy term for an ordered group of elements) class(c(TRUE, FALSE))[1] "logical"# we can force ('coerce', in R jargon) the vector to be numeric as.numeric(c(TRUE, FALSE))[1] 1 0This has interesting implications. First, is you have a logical vector of many
TRUEs andFALSEs, you can quickly count the number ofTRUEs by just taking the sum of the vector:# consider vector of 50 logicals x[1] FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE TRUE TRUE [12] FALSE TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE FALSE TRUE [23] TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSE [34] FALSE FALSE TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE [45] FALSE TRUE TRUE TRUE TRUE FALSE# number of TRUEs sum(x)[1] 32[1] 18Second, you can perform all sorts of arithmetic operations on logicals:
# TRUE/FALSE can be shortened to T/F T + T[1] 2F - T[1] -1(T * T) + F[1] 1Third, you can coerce numeric elements to valid logicals:
# zero is FALSE as.logical(0)[1] FALSE# everything else is TRUE as.logical(c(-1, 1, 12, -231.3525))[1] TRUE TRUE TRUE TRUENow, you may wonder that use this can possible be? Well, this way you can perform basic logical operations, such as AND, OR, and XOR (see section “Handy functions that return logicals” below):
# x * y is equivalent to x AND y as.logical(T * T)[1] TRUEas.logical(T * F)[1] FALSEas.logical(F * T)[1] FALSEas.logical(F * F)[1] FALSE# x + y is equivalent to x OR y as.logical(T + T)[1] TRUEas.logical(T + F)[1] TRUEas.logical(F + T)[1] TRUEas.logical(F + F)[1] FALSE# x - y is equivalent to x XOR y (eXclusive OR, either-or) as.logical(T - T)[1] FALSEas.logical(T - F)[1] TRUEas.logical(F - T)[1] TRUEas.logical(F - F)[1] FALSE"factor", factors are a bit weird. They are used mainly for tellingRthat a vector represents a categorical variable. For instance, you can be comparing two groups, treatment and control.# create a vector of 15 "control"s and 15 "treatment"s # rep stands for 'repeat', which is exactly what the function does x <- rep(c("control", "treatment"), each = 15) x[1] "control" "control" "control" "control" "control" [6] "control" "control" "control" "control" "control" [11] "control" "control" "control" "control" "control" [16] "treatment" "treatment" "treatment" "treatment" "treatment" [21] "treatment" "treatment" "treatment" "treatment" "treatment" [26] "treatment" "treatment" "treatment" "treatment" "treatment"# turn x into a factor x <- as.factor(x) x[1] control control control control control control [7] control control control control control control [13] control control control treatment treatment treatment [19] treatment treatment treatment treatment treatment treatment [25] treatment treatment treatment treatment treatment treatment Levels: control treatmentThe first thing to notice is the line under the last printout that says “
Levels: control treatment”. This informs you thatxis now a factor with two levels (or, a categorical variable with two categories).Second thing you should take note of is that the words
controlandtreatmentdon’t have quotes around them. This is another wayRuses to tell you this is a factor.With factors, it is important to understand how they are represented in
R. Despite, what they look like, under the hood, they are numbers. A one-level factor is a vector of1s, a two-level factor is a vector of1s and2s, a n-level factor is a vector of1s,2s,3s … ns. The levels, in our casecontrolandtreatment, are just labels attached to the1s and2s. Let’s demonstrate this:typeof(x)[1] "integer"# integer is fancy for "whole number" # we can coerce factors to numeric, thus stripping the labels as.numeric(x)[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2# see the labels levels(x)[1] "control" "treatment"The labels attached to the numbers in a factor can be whatever. Let’s say that in your raw data file, treatment group is coded as 1 and control group is coded as 0.
Since
xis now a factor with levels0and1, we know that it is stored inRas a vector of1s and2s and the zeros and ones, representing the groups, are only labels:The fact that factors in
Rare represented as labelled integers has interesting implications some of you have already come across. First, certain functions will coerce factors into numeric vectors which can shake things up. This happened when you usedcbind()on a factor with levels0and1:x[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Levels: 0 1# let's bind the first 15 elements and the last 15 elements together as columnscbind(x[1:15], x[16:30])[,1] [,2] [1,] 1 2 [2,] 1 2 [3,] 1 2 [4,] 1 2 [5,] 1 2 [ reached getOption("max.print") -- omitted 10 rows ]# printout truncated to first 5 rows to save spacecbind()binds the vectors you provide into the columns of a matrix. Since matrices (yep, that’s the plural of ‘matrix’; also, more on matrices later) can only containlogical,numeric, andcharacterelements, thecbind()function coerces the elements of thexfactor (haha, the X-factor) intonumeric, stripping the labels and leaving only1s and2s.The other two consequences of this labelled numbers system stem from the way the labels are stored. Every
Robject comes with a list of so called attributes attached to it. These are basically information about the object. For objects of classfactor, the attributes include its levels (or the labels attached to the numbers) and class:attributes(x)$levels [1] "0" "1" $class [1] "factor"So the labels are stored separately of the actual elements. This means, that even if you delete some of the numbers, the labels stay the same. Let’s demonstrate this implication on the
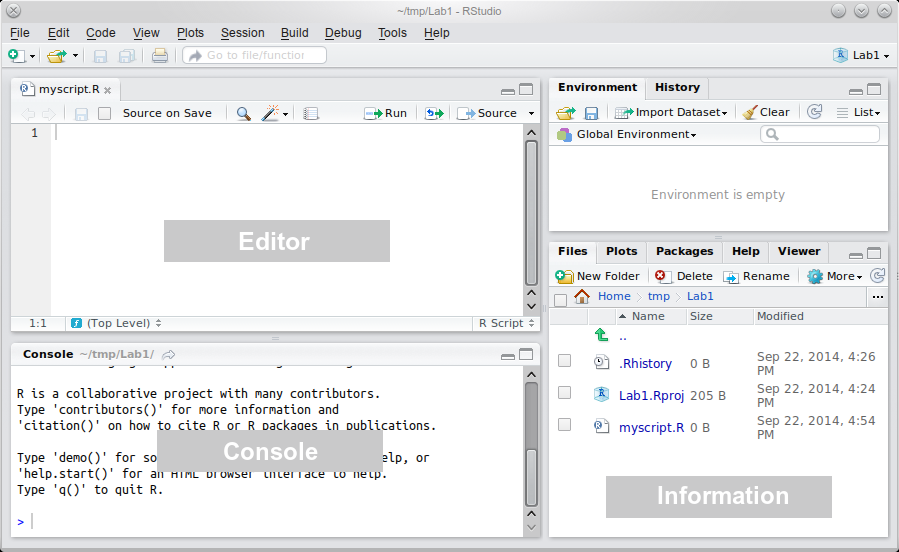
plot()function. This function is smart enough to know that if you give it a factor it should plot it using a bar chart, and not a histogram or a scatter plot:plot(x)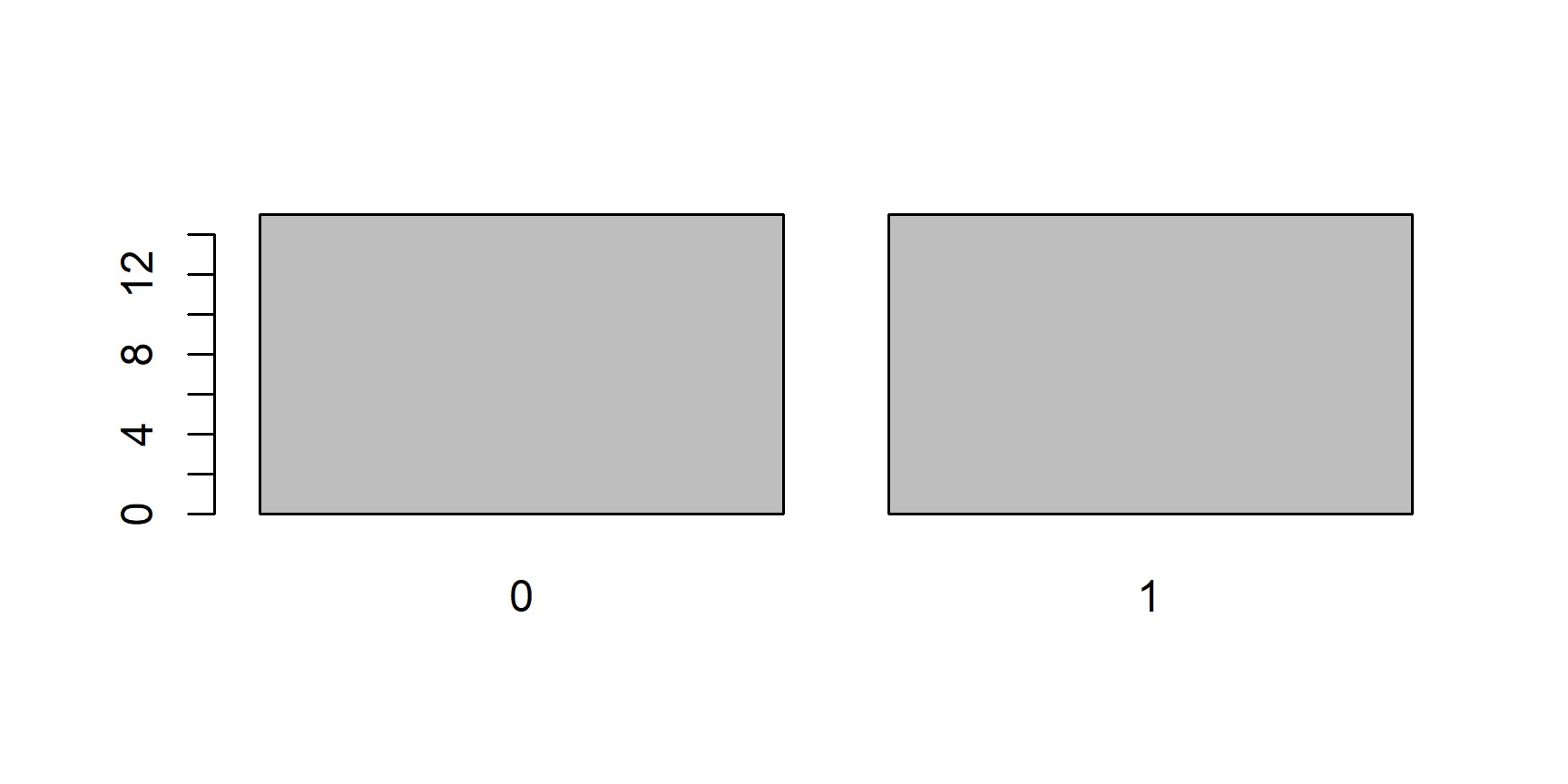
Now, let’s take the first 15 elements of
x, which are all0s and plot them:Even though our new object
yonly includes0s, thelevelsattribute still tellsRthat this is a factor of (at least potentially) two levels:"0"and"1"and soplot()leaves a room for the1s.The last consequence is directly related to this. Since the levels of an object of class
factorare stored as its attributes, any additional values put inside the objects will be invalid and turned intoNAs (Rwill warn us of this). In other words, you can only add those values that are among the ones produced bylevels()to an object of classfactor:# try adding invalid values -4 and 3 to the end of vector x x[31:32] <- c(-4, 3) x[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 [14] 0 0 1 1 1 1 1 1 1 1 1 1 1 [27] 1 1 1 1 <NA> <NA> Levels: 0 1The only way to add these values to a factor is to first coerce it to
numeric, then add the values, and then turn it back intofactor:# coerce x to numeric x <- as.numeric(x[1:30]) class(x)[1] "numeric"# but remember that 0s and 1s are now 1s and 2s! x[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2# so subtract 1 to make the values 0s and 1s again x <- x - 1 # add the new values x <- c(x, -4, 3) # back into fractor x <- as.factor(x) x[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 [23] 1 1 1 1 1 1 1 1 -4 3 Levels: -4 0 1 3# SUCCESS! # reset x <- as.factor(rep(0:1, each = 15)) # one-liner x <- as.factor(c(as.numeric(x[1:30]) - 1, -4, 3)) x[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 [23] 1 1 1 1 1 1 1 1 -4 3 Levels: -4 0 1 3Told you factors were weird…
"ordered", finally, these are the same as factors but, in addition to having levels, these levels are ordered and thus allow comparison (notice theLevels: 0 < 1below):# coerce x to numeric x <- as.ordered(rep(0:1, each = 15)) x[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Levels: 0 < 1# we can now compare the levels x[1] < x[30][1] TRUE[1] NAObjects of class
orderedare useful for storing ordinal variables, e.g., age group.
In addition to these five sorts of elements, there are three special wee snowflakes:
NA, stands for “not applicable” and is used for missing data. Unlike other kinds of elements, it can be bound into a vector along with elements of any class.NaN, stands for “not a number”. It is technically of classnumericbut only occurs as the output of invalid mathematical operations, such as dividing zero by zero or taking a square root of a negative number:Inf(or-Inf), infinity. Reserved for division of a non-zero number by zero (no, it’s not technically right):235/0[1] Inf-85.123/0[1] -Inf
Data structures
So that’s most of what you need to know about elements. Let’s talk about putting elements together. As mentioned above, elements can be grouped in various data structures. These differ in the ways in which they arrange elements:
vectors arrange elements in a line. they don’t have dimensions and can only contain elements of same class (e.g.,
"numeric","character","logical").# a vector letters[5:15][1] "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o"If you try to force elements of different classes to a single vector, they will all be converted to the most complex class. The order of complexity, from least to most complex, is:
logical,numeric, andcharacter. Elements of classfactorandorderedcannot be meaningfully bound in a vector with other classes (nor with each other): they either get converted tonumeric,character- if you’re lucky - or toNA.# c(logical, numeric) results in numeric x <- c(T, F, 1:6) x[1] 1 0 1 2 3 4 5 6class(x)[1] "integer"# integer is like numeric but only for whole numbers to save computer memory # adding character results in character x <- c(x, "foo") # the numbers 1-6 are not numeric any more! x[1] "1" "0" "1" "2" "3" "4" "5" "6" "foo"class(x)[1] "character"matrices arrange elements in a square/rectangle, i.e., a two-dimensional arrangement of rows and columns. They can also only accommodate elements of the same class and cannot store attributes of elements. That means, you can’t use them to store (ordered) factors.
[,1] [,2] [,3] [,4] [,5] [1,] 1.055165 -0.1471338 0.3655892 1.4756397 1.2200063 [2,] -0.312205 1.3333199 2.0918949 -0.2479756 1.9722208 [3,] 2.900048 0.3400205 0.8601729 -1.8949090 1.6148427 [4,] 0.253823 -0.1885970 0.3777971 2.1995795 -0.2421898[1] 0 1 0 1 1 1 1 0 1 1 Levels: 0 1# not factors any more! matrix(x, ncol = 5)[,1] [,2] [,3] [,4] [,5] [1,] "0" "0" "1" "1" "1" [2,] "1" "1" "1" "0" "1"lists arrange elements in a collection of vectors or other data structures. Different vectors/structures can be of different lengths and contain elements of different classes. Elements of lists and, by extension, data frames can be accessed using the
$operator, provided we gave them names.# a list my_list <- list( # 1st element of list is a numeric matrix A = matrix(rnorm(20, 1, 1), ncol = 5), # 2nd element is a character vector B = letters[1:5], # third is a data.frame C = data.frame(x = c(1:3), y = LETTERS[1:3]) ) my_list$A [,1] [,2] [,3] [,4] [,5] [1,] 0.76931823 -1.08618490 0.9681657 1.4600036 0.4959855 [2,] 0.72052941 0.88221429 0.1313416 -0.4708397 1.6079313 [3,] 1.59016176 -0.05850948 1.6047298 2.3353268 2.0576108 [4,] -0.07917997 -0.44227655 1.7916259 1.1658096 1.7367261 $B [1] "a" "b" "c" "d" "e" $C x y 1 1 A 2 2 B 3 3 C# we can use the $ operator to access NAMED elements of lists my_list$B[1] "a" "b" "c" "d" "e"# this is also true for data frames my_list$C$x[1] 1 2 3# but not for vectors or matrices my_list$A$1Error: <text>:2:11: unexpected numeric constant 1: # but not for vectors or matrices 2: my_list$A$1 ^data frames are lists but have an additional constraint: all the vectors of a
data.framemust be of the same length. That is the reasons why your datasets are always rectangular.arrays are matrices of n number of dimensions. Matrix is always a square/rectangle. An
arraycan also be a cube, or a higher dimensional structure. Admittedly, this is tricky to visualise but it is true., , 1 [,1] [,2] [,3] [,4] [,5] [1,] 2.5976880 1.5184335 -0.1606104 1.1669416 -0.7400089 [2,] 1.2160238 1.0783854 0.7216185 1.1826940 1.7860680 [3,] 0.4402993 -0.5678174 -0.4668042 1.6195435 1.8004761 [4,] 1.4861099 1.3684519 -1.0449207 -0.1886814 1.5040799 , , 2 [,1] [,2] [,3] [,4] [,5] [1,] 1.1476941 1.11917744 -0.1776244 2.72380113 -0.08240104 [2,] 1.2684743 1.29151023 1.7625905 1.02446040 1.31825629 [3,] 0.2606121 0.11962100 2.1697031 -1.32070330 2.55588637 [4,] -0.7122300 0.03364262 -0.6044303 -0.07403524 2.94666277 , , 3 [,1] [,2] [,3] [,4] [,5] [1,] 2.1113354 2.7328277 0.7931835 1.08066355 0.9086148 [2,] -0.8837650 -0.9711982 0.6291291 0.27657309 2.6004920 [3,] -0.1937936 0.7128997 0.1227985 1.30140982 1.2998969 [4,] 1.2716775 0.9521639 1.2071021 0.05938047 0.1566912
Different data structures are useful for different things but bear in mind that, ultimately, they are all just bunches of elements. This understanding is crucial for working with data.
There are only three ways to ask for elements
Now that you understand that all data boil down to elements, let’s look at how to ask R for the elements you want.
As the section heading suggests, there are only three ways to do this:
- indices
- logical vector
- names (only if elements are named, usually in lists and data frames)
Let’s take a closer look at these ways one at a time.
Indices
The first way to ask for an element is to simply provide the numeric position of the desired element in the structure (vector, list…) in a set of square brackets [] at the end of the object name:
x <- c("I", " ", "l", "o", "v", "e", " ", "R")
# get the 6th element
x[6]
[1] "e"
To get more than just one element at a time, you need to provide a vector of indices.
For instance, to get the elements 3-6 of x, we can do:
Remember that some structures can contain as their elements other structures.
For example asking for the first element of my_list will return:
my_list[1]
$A
[,1] [,2] [,3] [,4] [,5]
[1,] 0.76931823 -1.08618490 0.9681657 1.4600036 0.4959855
[2,] 0.72052941 0.88221429 0.1313416 -0.4708397 1.6079313
[3,] 1.59016176 -0.05850948 1.6047298 2.3353268 2.0576108
[4,] -0.07917997 -0.44227655 1.7916259 1.1658096 1.7367261
The $A at the top of the output indicates that we have accessed the element A of my_list but not really accessed the matrix itself.
Thus, at this stage, we wouldn’t be able to ask for its elements.
To access the matrix contained in my_list$A, we need to write either exactly that, or use double brackets:
my_list[[1]]
[,1] [,2] [,3] [,4] [,5]
[1,] 0.76931823 -1.08618490 0.9681657 1.4600036 0.4959855
[2,] 0.72052941 0.88221429 0.1313416 -0.4708397 1.6079313
[3,] 1.59016176 -0.05850948 1.6047298 2.3353268 2.0576108
[4,] -0.07917997 -0.44227655 1.7916259 1.1658096 1.7367261# with the $A now gone from output, we can access the matrix itself
my_list[[1]][1]
[1] 0.7693182
As discussed above, some data structures are dimensionless (vectors, lists), while others are arranged in n-dimensional rectangles (where n > 1).
When indexing/subsetting elements of dimensional structures, we need to provide coordinates of the elements for each dimension.
This is done by providing n numbers or vectors in the []s separated by a comma.
A matrix, for instance has 2 dimensions, rows and columns.
The first number/vector in the []s represents rows and the second columns.
Leaving either position blank will return all rows/columns:
mat <- matrix(LETTERS[1:20], ncol = 5)
mat
[,1] [,2] [,3] [,4] [,5]
[1,] "A" "E" "I" "M" "Q"
[2,] "B" "F" "J" "N" "R"
[3,] "C" "G" "K" "O" "S"
[4,] "D" "H" "L" "P" "T" # blank spaces technically not needed but improve code readability
mat[1, ] # first row
[1] "A" "E" "I" "M" "Q"mat[ , 1] # first column
[1] "A" "B" "C" "D"mat[c(2, 4), ] # rows 2 and 4, notice the c()
[,1] [,2] [,3] [,4] [,5]
[1,] "B" "F" "J" "N" "R"
[2,] "D" "H" "L" "P" "T" mat[c(2, 4), 1:3] # elements 2 and 4 of columns 1-3
[,1] [,2] [,3]
[1,] "B" "F" "J"
[2,] "D" "H" "L"
To get the full matrix, we simply type its name. However, you can think of the same operation as asking for all rows and all columns of the matrix:
mat[ , ] # all rows, all columns
[,1] [,2] [,3] [,4] [,5]
[1,] "A" "E" "I" "M" "Q"
[2,] "B" "F" "J" "N" "R"
[3,] "C" "G" "K" "O" "S"
[4,] "D" "H" "L" "P" "T"
The same is the case with data frames:
df <- data.frame(id = LETTERS[1:6],
group = rep(c("Control", "Treatment"), each = 3),
score = rnorm(6, 100, 20))
df
id group score
1 A Control 90.98199
2 B Control 97.49292
3 C Control 102.92184
4 D Treatment 98.79165
5 E Treatment 87.10690
6 F Treatment 88.11209df[1, ] # first row
id group score
1 A Control 90.98199df[4:6, c(1, 3)]
id score
4 D 98.79165
5 E 87.10690
6 F 88.11209
This [row, column] system can be extended to multiple dimensions.
As we said above, arrays can have n dimensions and so we need n positions in the []s to ask for elements:
, , 1
[,1] [,2] [,3] [,4] [,5]
[1,] 1.7707501 0.7524663 1.425150 0.49733345 0.4870223
[2,] 1.1383839 0.6776926 0.403361 1.50783347 1.2864144
[3,] 0.2674704 1.4581483 2.251834 0.09147882 1.8825147
[4,] 2.5134044 0.2891996 1.171600 0.87606133 0.1450124
, , 2
[,1] [,2] [,3] [,4] [,5]
[1,] 1.9835903 0.5433640 0.6031648 0.6784301 -0.1070031
[2,] 0.9048236 -0.1387803 0.7941896 1.3382661 1.8920177
[3,] -0.1375305 0.1514546 1.0429116 2.0954125 2.3287705
[4,] 0.7669415 2.4522680 1.8792214 0.1113503 2.3916659
, , 3
[,1] [,2] [,3] [,4] [,5]
[1,] 2.45591438 -0.2668876 2.6124300 -1.2737003 1.7063435
[2,] -0.04572805 -0.8134289 1.5681852 1.0479657 -1.4018941
[3,] 1.14437886 2.1435908 1.6348806 1.4219561 0.6546685
[4,] 1.21282827 -0.7582147 0.8400534 0.9377301 -0.4833443arr_3d[1, , ] # first row-slice
[,1] [,2] [,3]
[1,] 1.7707501 1.9835903 2.4559144
[2,] 0.7524663 0.5433640 -0.2668876
[3,] 1.4251497 0.6031648 2.6124300
[4,] 0.4973334 0.6784301 -1.2737003
[5,] 0.4870223 -0.1070031 1.7063435arr_3d[1, 2:4, 3] # elements in row 1 of columns 2-4 in the 3rd space of the 3rd dimension
[1] -0.2668876 2.6124300 -1.2737003
While 3D arrays can still be visualised as cubes (or rectangular cuboids), higher-n-dimensional arrays are trickier.
For instance, a 4D array would have a separate cuboid in every position of [x, , , ], [ , y, , ], [\,\,\z,\], and[\,\,\,\q]`.
You are not likely to come across 3+ dimensional arrays but it is good to understand that, in principle, they are just extensions of 2D arrays (matrices) and thus same rules apply.
Take home message: when using indices to ask for elements, remember that to request more than one, you need to give a vector of indices (i.e., numbers bound in a c()).
Also remember that some data structures need you to specify dimensions separated by a comma (most often just rows and columns for matrices and data frames).
Logical vectors
The second way of asking for elements is by putting a vector of logical (AKA Boolean) values in the []s.
An important requirement here is that the vector must be the same length as the one being subsetted.
So, for a vector with three elements, we need to provide three logical values, TRUE for “I want this one” and FALSE for “I don’t want this one”.
Let’s demonstrate this on the same vector we used for indices:
All the other principles we talked about regarding indexing apply also to logical vectors. Note also, that higher 2D structures need a logical row vector and a logical column vector:
# recall our mat
mat
[,1] [,2] [,3] [,4] [,5]
[1,] "A" "E" "I" "M" "Q"
[2,] "B" "F" "J" "N" "R"
[3,] "C" "G" "K" "O" "S"
[4,] "D" "H" "L" "P" "T" # rows 2 and 4
mat[c(T, F, T, F), ]
[,1] [,2] [,3] [,4] [,5]
[1,] "A" "E" "I" "M" "Q"
[2,] "C" "G" "K" "O" "S" [1] "D" "H"# you can even COMBINE the two ways!
mat[4, c(T, T, F, F, F)]
[1] "D" "H"
And as if vectors weren’t enough, you can even use matrices of logical values to subset matrices and data frames:
[,1] [,2] [,3]
[1,] FALSE FALSE FALSE
[2,] FALSE FALSE FALSE
[3,] FALSE FALSE FALSE
[4,] TRUE FALSE TRUE
[5,] TRUE FALSE TRUE
[6,] TRUE FALSE TRUEdf[mat_logic]
[1] "D" "E" "F" " 98.79165" " 87.10690"
[6] " 88.11209"
Notice, however, that the output is a vector so two things happened: first, the rectangular structure has been erased and second, since vectors can only contain elements of the same class (see above), the numbers got converted into character strings (hence the ""s).
Nevertheless, this method of subsetting using logical matrices can be useful for replacing several values in different rows and columns with another value:
# replace with NAs
df[mat_logic] <- NA
df
id group score
1 A Control 90.98199
2 B Control 97.49292
3 C Control 102.92184
4 <NA> Treatment NA
5 <NA> Treatment NA
6 <NA> Treatment NA
To use a different example, take the function lower.tri().
It can be used to subset a matrix in order to get the lower triangle (with or without the diagonal).
Consider matrix mat2 which has "L"s in its lower triangle, "U"s in its upper triangle, and "D"s on the diagonal:
[,1] [,2] [,3] [,4]
[1,] "D" "U" "U" "U"
[2,] "L" "D" "U" "U"
[3,] "L" "L" "D" "U"
[4,] "L" "L" "L" "D"
Let’s use lower.tri() to ask for the elements in its lower triangle:
Adding the , diag = T will return the lower triangle along with the diagonal:
mat2[lower.tri(mat2, diag = T)]
[1] "D" "L" "L" "L" "D" "L" "L" "D" "L" "D"# we got only "L"s and "D"s
So what does the function actually do? What is this sorcery? Let’s look at the output of the function:
lower.tri(mat2)
[,1] [,2] [,3] [,4]
[1,] FALSE FALSE FALSE FALSE
[2,] TRUE FALSE FALSE FALSE
[3,] TRUE TRUE FALSE FALSE
[4,] TRUE TRUE TRUE FALSESo the function produces a matrix of logicals, the same size as out mat2, with TRUEs in the lower triangle and FALSEs elsewhere.
What we did above is simply use this matrix to subset mat2[].
If you’re curious how the function produces the logical matrix then, first of all, that’s great, keep it up and second, you can look at the code wrapped in the lower.tri object (since functions are only objects of a special kind with code inside instead of data):
lower.tri
function (x, diag = FALSE)
{
x <- as.matrix(x)
if (diag)
row(x) >= col(x)
else row(x) > col(x)
}
<bytecode: 0x0000000015a39ab0>
<environment: namespace:base>Right, let’s see.
If we set the diag argument to TRUE the function returns row(x) >= col(x).
If we leave it set to FALSE (default), it returns row(x) > col(x).
Let’s substitute x for our mat2 and try it out:
row(mat2)
[,1] [,2] [,3] [,4]
[1,] 1 1 1 1
[2,] 2 2 2 2
[3,] 3 3 3 3
[4,] 4 4 4 4col(mat2)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 1 2 3 4
[3,] 1 2 3 4
[4,] 1 2 3 4 [,1] [,2] [,3] [,4]
[1,] TRUE FALSE FALSE FALSE
[2,] TRUE TRUE FALSE FALSE
[3,] TRUE TRUE TRUE FALSE
[4,] TRUE TRUE TRUE TRUE [1] "D" "L" "L" "L" "D" "L" "L" "D" "L" "D" [,1] [,2] [,3] [,4]
[1,] FALSE FALSE FALSE FALSE
[2,] TRUE FALSE FALSE FALSE
[3,] TRUE TRUE FALSE FALSE
[4,] TRUE TRUE TRUE FALSE[1] "L" "L" "L" "L" "L" "L"
MAGIC!
Take home message: When subsetting using logical vectors, the vectors must be the same length as the vectors you are subsetting. The same goes for logical matrices: they must be the same size as the matrix/data frame you are subsetting.
Complementary subsetting
Both of the aforementioned ways of asking for subsets of data can be inverted.
For indices, you can simply put a - sign before the vector:
# elements 3-6 of x
x[3:6]
[1] "l" "o" "v" "e"# invert the selection
x[-(3:6)]
[1] "I" " " " " "R"#equivalent to
x[c(1, 2, 7, 8)]
[1] "I" " " " " "R"
For logical subsetting, you need to negate the values.
That is done using the logical negation operator ‘!’ (AKA “not”):
y <- T
y
[1] TRUE# negation
!y
[1] FALSE# also works for vectors and matrices
mat_logic
[,1] [,2] [,3]
[1,] FALSE FALSE FALSE
[2,] FALSE FALSE FALSE
[3,] FALSE FALSE FALSE
[4,] TRUE FALSE TRUE
[5,] TRUE FALSE TRUE
[6,] TRUE FALSE TRUE!mat_logic
[,1] [,2] [,3]
[1,] TRUE TRUE TRUE
[2,] TRUE TRUE TRUE
[3,] TRUE TRUE TRUE
[4,] FALSE TRUE FALSE
[5,] FALSE TRUE FALSE
[6,] FALSE TRUE FALSEdf[!mat_logic]
[1] "A" "B" "C" "Control" "Control"
[6] "Control" "Treatment" "Treatment" "Treatment" " 90.98199"
[11] " 97.49292" "102.92184"
Names - $ subsetting
We already mentioned the final way of subsetting elements when we talked about lists and data frames.
To subset top-level elements of a named list or columns of a data frame, we can use the $ operator.
df$group
[1] "Control" "Control" "Control" "Treatment" "Treatment"
[6] "Treatment"What we get is a single vector that can be further subsetted using indices or logical vectors:
df$group[c(3, 5)]
[1] "Control" "Treatment"
Bear in mind that all data cleaning and transforming ultimately boils down to using one, two, or all of these three ways of subsetting elements!
Think of commands in terms of their output
In order to be able to manipulate your data, you need to understand that any chunk of code is just a formal representation of what the code is supposed to be doing, i.e., its output.
That means that you are free to put code inside []s but only so long as the output of the code is either a numeric vector (of valid values - you cannot ask for x[c(3, 6, 7)] if x has only six elements) or a logical vector/matrix of the same length/size as the object that is being subsetted.
Put any other code inside []s and R will return an error (or even worse, quietly produce some unexpected behaviour)!
So the final point we would like to stress is that you need to…
Know what to expect
You should not be surprised by the outcome of R.
If you are, that means you do not entirely understand what you asked R to do.
A good way to practice this understanding is to tell yourself what form of output and what values you expect a command to return.
For instance, in the code above, we did x[-(3:6)].
Ask yourself what does the -(3:6) return.
How and why is it different from -3:6?
What will happen if you do x[-3:6]?
-(3:6)
[1] -3 -4 -5 -6-3:6
[1] -3 -2 -1 0 1 2 3 4 5 6x[-3:6]
Error in x[-3:6]: only 0's may be mixed with negative subscriptsIf any of the output above surprised you, try to understand why. What were your expectations? Do you now, having seen the actual output, understand what those commands do?
Some of you were wondering why, when replacing values in column 1 of matrix mat that are larger than, say, 2 with NAs, you had to specify the column several times, e.g.:
mat[mat[ , 1] > 2, 1] <- NA
## 2 instances of mat[ , 1] in total:
# 1.
outer
mat[..., 1]
# 2.
comparison
mat[ , 1] > ...
Let’s consider matrix mat:
[,1] [,2] [,3] [,4] [,5]
[1,] -0.4821663 -1.235421 0.09837657 0.2507154 1.58974540
[2,] 0.8314073 -1.728620 1.31394902 -0.9550187 -1.08255274
[3,] 2.4322500 -1.426386 0.56463977 0.3002515 0.63186928
[4,] 0.8201293 -1.051542 -1.55258377 0.2782249 -1.58621500
[5,] -1.3918933 1.410444 1.20531294 -0.2560778 -0.05314628
[,6]
[1,] -0.2969522
[2,] -0.3459194
[3,] 0.6151551
[4,] -0.2604405
[5,] 0.6354582and think of the command in terms of the expected outcome of its constituent elements.
The logical operator ‘>’ returns a logical vector corresponding to the answer to the question “is the value to the left of the operator larger than that to the right of the operator?” The answer can only be TRUE or FALSE.
So mat[ , 1] > 2 will return:
[1] FALSE FALSE TRUE FALSE FALSEThere is no way of knowing that these values correspond to the 1st column of mat just from the output alone. That information has been lost.
This means that, if we type mat[mat[ , 1] > 2, ], we are passing a vector of T/Fs to the row position of the []s.
The logical vector itself contains no information about it coming from a comparison of the 1st row of mat to the value of 2.
So R can only understand the command as mat[c(FALSE, FALSE, TRUE, FALSE, FALSE), ] and will try to recycle the vector FALSE, FALSE, TRUE, FALSE, FALSE for every column of mat:
mat[mat[ , 1] > 2, ]
[1] 2.4322500 -1.4263864 0.5646398 0.3002515 0.6318693 0.6151551
If you want to only extract values from mat[ , 1] that correspond to the TRUEs, you must tell R that, hence the apparent (but not actual) repetition in mat[mat[ , 1] > 2, 1].
mat[mat[ , 1] > 2, 1] <- NA
mat
[,1] [,2] [,3] [,4] [,5]
[1,] -0.4821663 -1.235421 0.09837657 0.2507154 1.58974540
[2,] 0.8314073 -1.728620 1.31394902 -0.9550187 -1.08255274
[3,] NA -1.426386 0.56463977 0.3002515 0.63186928
[4,] 0.8201293 -1.051542 -1.55258377 0.2782249 -1.58621500
[5,] -1.3918933 1.410444 1.20531294 -0.2560778 -0.05314628
[,6]
[1,] -0.2969522
[2,] -0.3459194
[3,] 0.6151551
[4,] -0.2604405
[5,] 0.6354582
This feature might strike some as redundant but it is actually the only sensible way.
The fact that R is not trying to guess what columns of the data you are requesting from the syntax of the code used for subsetting the rows (and vice versa) means, that you can subset matrix A based on some comparison of matrix B (provided they are the same size).
Or, you can replace values of mat[ , 3] based on some condition concerning mat[ , 2].
That can be very handy!
It may take some time to get the hang of this but we cannot overstate the importance of knowing what the expected outcome of your commands is.
Putting it all together
Now that we’ve discussed the key principles of talking to computers, let’s solidify this new understanding using an example you will often encounter.
According to our second principle, if we want to keep it for later, we must put it in an object.
Let’s have a look at some health and IQ data stored in some data frame object called df:
Now, let’s replace all values of IQ that are further than \(\pm 2\) standard deviations from the mean of the variable with NAs.
First, we need to think conceptually and algorithmically about this task: What does it actually mean for a data point to be further than \(\pm 2\) standard deviations from the mean?
Well, that means that if \(Mean(x) = 100\) and \(std.dev(x) = 15.34\), we want to select all data points (elements of x) that are either smaller than \(100 - 2 \times 15.34 = 69.32\) or larger than \(100 + 2 \times 15.34 = 130.68\).
# let's start by calculating the mean
# (the outer brackets are there for instant printing)
# na.rm = T is there to disregard any potential NAs
(m_iq <- mean(df$IQ, na.rm = T))
[1] 99.99622# now let's get the standard deviation
(sd_iq <- sd(df$IQ, na.rm = T))
[1] 15.34238# now calculate the lower and upper critical values
(crit_lo <- m_iq - 2 * sd_iq)
[1] 69.31145(crit_hi <- m_iq + 2 * sd_iq)
[1] 130.681
This tells us that we want to replace all elements of df$IQ that are smaller than 69.31 or larger than 130.68.
Let’s do this!
# let's get a logical vector with TRUE where IQ is larger then crit_hi and
# FALSE otherwise
condition_hi <- df$IQ > crit_hi
# same for IQ smaller than crit_lo
condition_lo <- df$IQ < crit_lo
Since we want all data points that fulfil either condition, we need to use the OR operator.
The R symbol for OR is a vertical bar “|” (see bottom of document for more info on logical operators):
# create logical vector with TRUE if df$IQ meets
# condition_lo OR condition_hi
condition <- condition_lo | condition_hi
Next, we want to replace the values that fulfil the condition with NAs, in other words, we want to do a little subsetting.
As we’ve discussed, there are only two ways of doing this: indices and logicals.
If we heed principles 5 and 6, think of our code in terms of its output and know what to expect, we will understand that the code above returns a logical vector of length(df$IQ) with TRUEs in places corresponding to positions of those elements of df$IQ that are further than \(\pm 2SD\) from the mean and FALSEs elsewhere.
Let’s check:
condition
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
[11] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[21] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[31] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[41] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[51] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[71] TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
[81] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[91] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[101] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[111] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[121] FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[131] FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[141] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[151] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[161] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[171] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[181] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[191] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[201] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[211] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[221] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[231] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[241] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
[251] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[261] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
[271] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[281] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
[291] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[301] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[311] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[321] FALSE FALSE FALSE FALSE FALSE# now let's use this object to index out elements of df$IQ which
# fulfil the condition
df$IQ[condition]
[1] 20.00000 132.35251 58.85790 132.98465 58.24403 135.92026
[7] 132.92835 130.98682 61.39313 67.00030 135.09655 55.77873
[13] 68.37715
Finally, we want to replace these values with NAs.
That’s easy right?
All we need to do is to put this vector into []s next to df$IQ (or df[["IQ"]], df[ , "IQ"], df[ , 4], or different still, df[[4]]) and assign the value of NA to them:
df$IQ[condition] <- NA
# see the result (only rows with NAs in IQ)
df[is.na(df[[4]]), ]
ID Agegroup ExGroup IQ
10 10 1 1 NA
11 11 1 1 NA
71 71 1 2 NA
77 77 1 2 NA
122 122 1 2 NA
125 125 1 2 NA
133 133 1 2 NA
135 135 1 2 NA
171 171 2 1 NA
212 212 2 1 NA
247 247 2 2 NA
270 270 2 2 NA
288 288 2 2 NASUCCESS!
We replaced outlying values of IQ with NAs.
Or, to be pedantic (and that is a virtue when talking to computers), we took the labels identifying the elements mat[c(FALSE, FALSE, TRUE, FALSE, FALSE), ] of the df$IQ vector, put those labels on a bunch of NAs and burned the original elements.
All that because you cannot really change an R object.
Are there quicker ways?
You might be wondering if there are other ways of achieving the same outcome, perhaps with fewer steps. Well, aren’t you lucky, there are indeedor instance, you can put all of the code above in a single command, like this:
Of course, fewer commands doesn’t necessarily mean better code.
The above has the benefit of not creating any additional objects (m_iq, condition_lo, etc.) and not cluttering your environment.
However, it may be less intelligible to a novice R user (the annotation does help though).
A particularly smart and elegant way would be to realise that the condition above is the same as saying we want all the points xi for which \(|x_i - Mean(x)| > 2 \times 15.34\). The \(x_i - Mean(x)\) has the effect of centring x so that its mean is zero and the absolute value (\(|...|\)) disregards the sign. Thus \(|x| > 1\) is the same as \(x < -1\) OR \(x > 1\).
Good, so the condition we want to apply to subset the IQ variable of df is abs(df$IQ - mean(df$IQ, na.rm = T)) > 2 * sd(df$IQ, na.rm = T).
The rest, is the same:
This is quite a neat way of replacing outliers with NAs and code like this shows a desire to make things elegant and efficient.
However, all three approaches discussed above (and potentially others) are correct.
If it works, it’s fine!
Elementary, my dear Watson! ;)
Functions
Every operation on a value, vector, object, and other structures in R is done using functions.
You’ve already used several: c() is a function, as are <-, +, -, *, etc. A function is a special kind of object that takes some arguments and uses them to run the code contained inside of it.
Every function has the form function.name() and the arguments are given inside the brackets.
Arguments must be separated with a comma.
Different functions take different number of various arguments.
The help file brought up by the ?... gives a list of arguments used by the given function along with the description of what the arguments do and what legal values they take.
Let’s look at the most basic functions in R: the assignment operator <- and the concatenate function c().
Yes, <- is a function, even though the way it’s used differs from most other functions.
It takes exactly two arguments – a name of an object to the left of it and an object or a value to the right of it.
the output of this function is an object with the provided name containing the values assigned:
# arg 1: name function arg 2: value
x <- 3
# print x
x
[1] 3# arg 1: name function arg 2: object + value
y <- x + 7
y
[1] 10The c() function, on the other hand takes an arbitrary number of arguments, including none at all.
The arguments can either be single values (numeric, character, logical, NA), or objects.
The function then outputs a single vector consisting of all the arguments:
c(1, 5, x, 9, y)
[1] 1 5 3 9 10Packages
All functions in R, except the ones you write yourself or copy from online forums, come in packages.
These are essentially folders that contain all the code that gets run whenever you use a function along with help files and some other data.
Basic R installation comes with several packages and every time you open R or RStudio, some of these will get loaded, making the functions these packages contain available for you to use.
That’s why you don’t have to worry about packages when using functions such as c(), mean(), or plot().
Other functions however come in packages that either don’t get loaded automatically upon startup or need to be installed.
For instance, a very handy package for data visualisation that is not installed automatically is ggplot2.
If we want to make use of the many functions in this package, we need to first install it using the install.packages() command:
install.packages("ggplot2")
Notice that the name of the package is in quotes. This is important. Without the quotes, the command will not work!
You only ever need to install a package once. R will go online, download the package from the package repository and install it on your computer.
Once we’ve installed a package, we need to load it so that R can access the functions provided in the package.
This is done using the library() command:
Packages have to be loaded every session.
If you load a package, you can use its functions until you close R.
When you re-open it, you will have to load the package again.
For that reason, it is very useful to load all the packages you will need for your data processing, visualisation, and analysis at the very beginning of your script.
Now that we have made ggplot2 available for our current R session, we can use any of its functions.
For a quick descriptive plot of the a variable, we can use the qplot() function:
If you don’t install or load the package that contains the function you want to use, R will tell you that it cannot find the function.
Let’s illustrate this on the example of a function describe() from the package psych which is pre-installed but not loaded at startup:
describe(df$ID)
Error in describe(df$ID): could not find function "describe"Once, we load the psych package, R will be able to find the function:
Using functions
The ()s
As a general rule of thumb, the way to tell R that the thing we are calling is a function is to put brackets – () – after the name, e.g., data.frame(), rnorm(), or factor().
The only exception to this rule are operators – functions that have a convenient infix form – such as the assignment operators (<-, =), mathematical operators (+, ^, %%, …), logical operators (==, >, %in%, …), and a handful of others.
Even the subsetting square brackets [] are a functionowever, the infix form is just a shorthand and all of these can be used in the standard way functions are used:
2 + 3 # infix form
[1] 5`+`(2, 3) # prefix form, notice the backticks
[1] 5The above is to explain the logic behind a simple principle in R programming: If it is a function (used in its standard prefix form) then it must have ()s.
If it is not a function, then it must NOT have them.
If you understand this, you will never attempt to run commands like as.factor[x] or my_data(...)!
Specifying arguments
The vast majority of functions require you to give it at least one argument.
Arguments of a function are often named.
From the point of view of a user of a function, these names are only placeholders for some values we want to pass to the function.
In RStudio, you can type the name of a function, open the bracket and then press the Tab key to see a list of arguments the function takes.
You can try it now, type, for instance, sd( and press the Tab key.
You should see a pop-up list of two arguments – x = and na.rm = – appear.
This means, that to use the sd() function explicitly, we much give it two arguments: a numeric vector and a single logical value (technically, a logical vector of length 1):
The output of the function is NA because our vector contained an NA value and the na.rm = argument that removes the NAs was set to FALSE.
Try setting it to TRUE (or T if you’re a lazy typist) and see what R gives you.
Look what happens when we run the following command:
We didn’t specify the value of the na.rm = argument but the code worked anyway.
Why might that be…?
Default values of arguments
The reason for this behaviour is that functions can have arguments set to some value by default to facilitate the use of the functions in the most common situations by reducing the amount of typing.
Look at the documentation for the sd() function (by running ?sd in the console).
You should see that under “Usage” it reads sd(x, na.rm = FALSE).
This means that, by default, the na.rm = argument is set to FALSE and if you don’t specify its value manually, the function will run with this setting.
Re-visiting our example with the NA value, you can see that the output is as it was before:
Argument matching
You may have noticed a tiny change in the way the first argument was specified in the line above (coding is a lot about attention to detail!) – there is no x = in the code.
The reason why R is still able to understand what we meant is argument matching.
If no names are given to the arguments, R assumes they are entered in the order in which they were specified when the function was created.
This is the same order you can look up in the “Usage” section of the function documentation (using ?)
To give you another example, take rnorm() for instance.
If you pull up the documentation (AKA help) of the file with ?rnorm, you’ll see that it takes 3 arguments: n =, mean =, and sd =.
The latter two have default values but n = doesn’t so we must provide its value.
Setting the first argument to 10 and omitting the other 2 will generate a vector of 10 numbers drawn from a normal distribution with \(\mu = 0\) and \(\sigma=1\):
rnorm(10)
[1] -0.7518433 0.3575798 -0.4231625 0.3173492 0.9610531 -0.5929562
[7] 1.1406227 0.5375575 -0.3747863 -2.6891043Lets say we want to change the mean to -5 but keep standard deviation the same. Relying on argument matching, we can do:
rnorm(10, -5)
[1] -4.017823 -6.258214 -5.113746 -4.435332 -6.840417 -5.725059
[7] -4.295440 -4.956638 -4.936408 -4.707679However, if we want to change the sd = argument to 3 but leave mean = set to 0, we need to let R know this more explicitly.
There are several ways to do the same thing but they all rely on the principle that unnamed values will be interpreted in order of arguments:
rnorm(10, 0, 3) # keep mean = 0
[1] -0.5869053 -3.7089712 4.1902430 -0.7493729 -1.1789825 2.8443374
[7] 3.7686362 -2.6126934 1.5321707 -1.3758607rnorm(10, , 3) # skip mean = (DON'T DO THIS! it's illegible)
[1] 2.4504947 5.4091571 3.6503523 1.6291335 -0.3655094 1.0075295
[7] -2.1954416 1.2471465 0.9276066 -6.2682078If the arguments are named, they can be entered in any order:
rnorm(sd = 2, n = 10, mean = -100)
[1] -101.10377 -102.20943 -99.72367 -99.48686 -102.01520 -101.55307
[7] -102.05843 -101.27777 -100.87286 -102.33650The important point here is that if you give a function 4 (for example) unnamed values separated with commas, R will try to match them to the first 4 arguments of the function.
If the function takes fewer than arguments or if the values are not valid for the respective arguments, R will throw an error:
rnorm(100, 5, -3, 8) # more values than arguments
Error in rnorm(100, 5, -3, 8): unused argument (8)That is, it will throw an error if you’re lucky. If you’re not, you might get all sorts of unexpected behaviours:
rnorm(10, T, -7) # illegal values passed to arguments
[1] NaN NaN NaN NaN NaN NaN NaN NaN NaN NaNPassing vectors as arguments
The majority of functions – and you’ve already seen quite a few of these – have at least one argument that can take multiple values.
The x = (first) argument of sample() or the labels = argument of factor() are examples of these.
Imagine we want to sample 10 draws with replacement from the words “elf”, “orc”, “hobbit”, and “dwarf”.
Your intuition might be to write something like sample("elf", "orc", "hobbit", "dwarf", 10).
That will however not work:
sample("elf", "orc", "hobbit", "dwarf", 10, replace = T)
Error in sample("elf", "orc", "hobbit", "dwarf", 10, replace = T): unused arguments ("dwarf", 10)
Take a moment to ponder why this produces an error…
Yes, you’re right, it has to do with argument matchingRinterprets the above command as you passing five arguments to thesample()function, which only takes three arguments. Moreover, the second argumentsize =must be a positive number,replace =must be a single logical value, andprob =is a vector of numbers between 0 and 1 that must add up to 1 and the vector must be of the same length as the vector passed to the firstx =` argument.
As you can see, our command fails on most of these criteria.
So, how do we tell R that we want to pass the four races of Middle-earth to the first argument of sample()?
Well, we need to bind them into a single vector using the c() function:
Remember: If you want to pass a vector of values into a single argument of a function, you need to use an object in your environment containing the vector or a function that outputs a vector.
The basic one is c() but others work too, e.g., sample(5:50, 10) (the : operator returns a vector containing a complete sequence of integers between the specified values).
Passing objects as arguments
Everything in R is an object and thus the values passed as arguments to functions are also objects.
It is completely up to you whether you want to create the object ad hoc for the purpose of only passing it to a function or whether you want to pass to a function an object you already have in your environment.
For example, if our four races are of particular interest to us and we want to keep them for future use, we can assign them to the environment under some name:
ME_races <- c("elf", "orc", "hobbit", "dwarf")
ME_races # here they are
[1] "elf" "orc" "hobbit" "dwarf" Then, we can just use them as arguments to functions:
Function output
Command is a representation of its output
Any complete command in R, such as the one above is merely a symbolic representation of the output it returns.
Understanding this is crucialust like in a natural language, there are many ways to say the same thing, there are multiple ways of producing the same output in R.
It’s not called a programming language for nothing!
One-way street
Another important thing to realise is that, given that there are many ways to do the same thing in R, there is a sort of directionality to the relationship between a command and its output.
If you know what a function does, you can unambiguously tell what the output will be given specified arguments.
However, once the output is produced, there is no way R can tell what command was used.
Imagine you have three bakers making the same kind of bread: one uses the traditional kneading method, one uses the slap-and-fold technique, and one uses a mixer.
If you know the recipe and the procedure they are using, you will be able to tell what they’re making.
However, once you have your three loaves in front of you, you won’t be able to say which came from which baker.
It’s the same thing with commands in R!
This is the reason why some commands look like they’re repeating things beyond necessity. Take, for instance, this line:
mat[lower.tri(mat)] <- "L"
The lower.tri() function takes a matrix as its first argument and returns a matrix of logicals with the same dimensions as the matrix provided.
Once it returns its output, R has no way of knowing what matrix was used to produce it and so it has no clue that it has anything to do with our matrix mat.
That’s why, if we want to modify the lower triangle of mat, we do it this way.
Obviously, nothing is stopping you from creating the logical matrix by means of some other approach and then use it to subset mat but the above solution is both more elegant and more intelligible.
Knowe thine output as thou knowest thyself
Because more often than not you will be using function to create some object only so that you can feed it into another function, it is essential that you understand what you are asking R to do and know what result you are expecting.
There should be no surprises!
A good way to practice is to say to yourself what the output of a command will be before you run it.
For instance, the command factor(sample(1:4, 20, T), labels = ME_races) returns a vector of class factor and length 20 containing randomly sampled values labelled according to the four races of Middle-earth we worked with.
Output is an object
Notice that in the code above we passed the sample(1:4, 20, T) command as the first argument of factor().
This works because – as we mentioned earlier – a command is merely a symbolic representation of its output and because everything in R is an object.
This means that function output is also an object.
Depending on the particular function, the output can be anything from, e.g., a logical vector of length 1 through long vectors and matrices to huge data frames and complex lists of lists of lists…
For instance, the t.test() function returns a list that contains all the information about the test you might ever need:
List of 10
$ statistic : Named num 23.5
..- attr(*, "names")= chr "t"
$ parameter : Named num 99
..- attr(*, "names")= chr "df"
$ p.value : num 2.52e-42
$ conf.int : num [1:2] 4.43 5.24
..- attr(*, "conf.level")= num 0.95
$ estimate : Named num 4.84
..- attr(*, "names")= chr "mean of x"
$ null.value : Named num 0
..- attr(*, "names")= chr "mean"
$ stderr : num 0.206
$ alternative: chr "two.sided"
$ method : chr "One Sample t-test"
$ data.name : chr "rnorm(100, 5, 2)"
- attr(*, "class")= chr "htest"If we want to know the p-value of the above test, we can simply query the list accordingly:
t_output$p.value
[1] 2.523022e-42Because the command only represents the output object, it can be accessed in the same way. Say you are running some kind of simulation study and are only interested in the t-statistic of the test. Instead of saving the entire output into some kind of named object in the environment, you can simply save the t:
Where does the output go?
Let’s go back to discussing factor().
There’s another important issue that sometime causes a level of consternation among novice R users.
Imagine we have a data set and we want to designate one of its columns as a factor so that R knows that the column contains a categorical variable.
df <- data.frame(id = 1:10, x = rnorm(10))
df
id x
1 1 -0.65035157
2 2 -1.75580846
3 3 -0.01612903
4 4 -1.60192352
5 5 -2.05558512
6 6 -0.91542764
7 7 1.90594739
8 8 -1.11545359
9 9 -0.19819964
10 10 -0.40419480An intuitive way of turning id into a factor might be:
factor(df$id)
[1] 1 2 3 4 5 6 7 8 9 10
Levels: 1 2 3 4 5 6 7 8 9 10This, however, does not work:
class(df$id)
[1] "integer"The reason for this has to do with the fact that the argument-output relationship is directional.
Once the object inside df$id is passed to factor(), R forgets about the fact that it had anything to do with df or one of its columns.
It has therefore no way of knowing that you want to be modifying a column of a data frame.
Because of that, the only place factor() can return the output to is the one it uses by default.
Console
The vast majority of functions return their output into the console.
factor() is one of these functions.
That’s why when you type in the command above, you will see the printout of the output in the console.
Once it’s been returned, the output is forgotten about – R can’t see the console or read from it!
This is why factor(df$id) does not turn the id column of id into a factor.
Environment
A small number of functions return a named object to the global R environment, where you can see, access, and work with it.
The only one you will need to use for a long time to come (possibly ever) is the already familiar assignment operator <-.
You can use <- to create new objects in the environment or re-assign values to already existing names.
So, if you want to turn the id column of df into a factor you need to reassign some new object to df$id.
What object?
Well, the one returned by the factor(...) command above:
df$id <- factor(df$id)
As you can see, there is no printout now because the output of factor() has been passed into the assignment function which directed it into the df$id object.
Let’s make sure it really worked:
class(df$id)
[1] "factor"Graphical device
Functions that create graphics return their output into something called the graphical device.
It is basically the thing responsible for drawing stuff on the screen of your computer.
You’ve already encountered some of these functions – plot(), par(), lines(), abline().
Files
Finally, there are functions that can write output into all sorts of files.
For instance, if you want to save a data frame into a .csv file, you can use the read.csv() function.
Of course, you can redirect where particular output gets sent, just like we did with df$id <- factor(...).
For instance, you can save a plot into the global environment using assignment:
my_plot
$breaks
[1] -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0 2.5 3.0
[14] 3.5
$counts
[1] 4 13 50 75 180 179 193 145 97 35 21 7 1
$density
[1] 0.008 0.026 0.100 0.150 0.360 0.358 0.386 0.290 0.194 0.070 0.042
[12] 0.014 0.002
$mids
[1] -2.75 -2.25 -1.75 -1.25 -0.75 -0.25 0.25 0.75 1.25 1.75 2.25
[12] 2.75 3.25
$xname
[1] "rnorm(1000)"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"Alternatively, you can export it by creating a new graphical device inside of a file:
Making the computer do the heavy lifting
Avoiding repetition and avoiding repetition
Data manipulation and analysis often carries the burden of repetition. For instance, we might have to clean each of several many variables according to the same set of rules or repeat the same statistical test over many variables (and of course, adequately correct for multiple testing afterwards!).Every time you encounter repetitive tasks like these, you should start thinking about how to delegate as much of the legwork as possible on the computer.
This is where loops come in very handy.
They are used to repeat a block of code an arbitrary number of times.
Let’s look at the anatomy of a loop in R:
for (i in n) {
# code
}
the for () {} bit is just syntax and it’s sole function is to tell R that this is a loop.
The bit in () defines the iterator variable i and the vector n over which the loop iterates.
So for (i in 1:10) will be a loop that runs through 10 times.
First, it will assign i the value of 1 and run the rest of the code.
Then, it will assign it the next value in the n vector, e.g., 2 and run the code again.
It will repeat until it runs out of elements of n.
To demonstrate:
for (i in 1:5) {
print(i)
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5As you can see, the loop printed the value of i for each of the 5 iterations.
The code in the body of the loop {} can do whatever you want.
you can use the current value of i to create, modify, or subset data structures, to do calculations with it, or simply not use it at all.
The world’s your oyster!
Finally, loops can be nested, if needed:
for (i in n) {
for (j in m) {
# code
}
}
This will run all the iterations of the inner loop for each iteration of the outer one.
You will often want to save the output of each iteration of the loop. There are again many ways to do this but a straight-forward one is to first create an empty object and then start combining it with the output of the loop:
Let’s see how we can use loops to do something useful. Imagine we have 5 numeric variables and we want to report their correlations along with p-values. It would be nice to put everything in a single correlation matrix with r coefficients in the upper triangle and the p-values in the lower, like this:
X1 X2 X3 X4 X5
X1 0.000 -0.014 0.472 0.530 -0.044
X2 0.888 0.000 0.001 -0.050 0.917
X3 0.000 0.988 0.000 0.297 -0.049
X4 0.000 0.622 0.003 0.000 -0.049
X5 0.667 0.000 0.626 0.629 0.000Let’s say, our data are stored in an object called cor_data that looks like this (first 6 rows):
head(cor_data)
X1 X2 X3 X4 X5
1 -0.2759918 0.6704138 -1.44894480 -1.1155792 0.5953214
2 -1.6977918 -2.3003277 -0.82142373 -0.4213708 -2.3137669
3 -0.7829298 -1.3527868 -0.72333713 0.4229719 -1.9272907
4 -1.2656664 1.4822161 0.04900518 -1.6888016 2.4054813
5 -1.1264350 0.6954408 -0.24592865 0.6653974 1.2573338
6 1.0899947 0.4561996 0.62385570 1.2912474 0.9328107Getting the correlation coefficients is simple, we can just use R’s cor() function:
cor(cor_data)
X1 X2 X3 X4 X5
X1 1.00000000 -0.014220520 0.471726103 0.53021685 -0.04362279
X2 -0.01422052 1.000000000 0.001477437 -0.04987034 0.91673218
X3 0.47172610 0.001477437 1.000000000 0.29655510 -0.04939428
X4 0.53021685 -0.049870336 0.296555099 1.00000000 -0.04891375
X5 -0.04362279 0.916732181 -0.049394285 -0.04891375 1.00000000As you can see, the matrix is symmetrical along its diagonal: the upper triangle is the same as the lower one.
What we want to do now is to replace the elements of the lower triangle with the p-values corresponding to the correlation coefficients.
To get the p-value for a correlation of two variables, we can use the cor.test() function:
cor.test(cor_data$X1, cor_data$X2)
Pearson's product-moment correlation
data: cor_data$X1 and cor_data$X2
t = -0.14079, df = 98, p-value = 0.8883
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.2100519 0.1827079
sample estimates:
cor
-0.01422052 The output of this function is a list and we can use $ to isolate the p-value:
cor.test(cor_data$X1, cor_data$X2)$p.value
[1] 0.8883247So what we need now is a loop that takes each pair of variables one at a time, gets the p-value from the cor.test() function and puts it the correct place in the correlation matrix.
For this, we need a nested loop, with one level defining the first of the pair of variables to correlate and the other defining the second:
cmat <- cor(cor_data) # stores correlation matrix in an object
for (i in 1:ncol(cor_data)) { # i goes from 1 to the number of variables in data - 5
for (j in i:ncol(cor_data)) { # j goes from i to number of vars in data
cmat[j, i] <- # jth row of ith column of cmat will be replaced with...
cor.test(cor_data[ , i], # cor.test p-value for ith variable...
cor_data[ , j])$p.value # ...and jth variable
}
}
# let's see what cmat looks like now, rounded to 3 decimal places
round(cmat, 3)
X1 X2 X3 X4 X5
X1 0.000 -0.014 0.472 0.530 -0.044
X2 0.888 0.000 0.001 -0.050 0.917
X3 0.000 0.988 0.000 0.297 -0.049
X4 0.000 0.622 0.003 0.000 -0.049
X5 0.667 0.000 0.626 0.629 0.000At this stage, this might not seem like an easy task but, with a little practice and dedication, you can learn how to use loops to save yourself a lot of time and effort!
The apply() family
Another way of telling R to do a repetitive task is using the apply() family functions.
These function take some data structure and apply any function to each element of that structure.
To illustrate, let’s look at apply().
Imagine we have a data frame df like this:
id X1 X2 X3 X4 X5
1 1 -0.21928235 -0.04661422 -0.18119589 0.8780239 -1.9560494
2 2 -0.18925670 -1.52372671 1.10450578 0.6644643 -1.2965841
3 3 -0.03311992 0.64979468 0.48261411 -0.6521869 -0.4407362
4 4 -0.05389948 0.18124055 0.01810066 0.1209297 0.4971647
5 5 1.01070937 -1.18156314 1.21591705 0.7567177 -1.2348908
6 6 0.16565502 -1.03543448 -0.45587029 -1.1324933 -1.3745648Let’s say we want to know which of the X1-X5 columns contains the largest value for each participant.
If we only take the first row, for example, then the task is easy, right?
df[1, 2:6]
X1 X2 X3 X4 X5
1 -0.2192824 -0.04661422 -0.1811959 0.8780239 -1.956049which.max(df[1, 2:6])
X4
4 If we want to know this bit of information for every row of the data frame, doing it manually is quite tedious.
We could instead use a for loop:
This loop iterates over the rows of df (for (i in 1:nrow(df))) and for each cycle it adds the output of the which.max() function to the max_col variable.
There is nothing wrong with this approach but it is a little wordy to write and not the fastest when it comes to computation time.
The apply() function can be used to achieve the same outcome faster and using less code:
So how does this work? apply() requires 3 arguments:
- X – a matrix (remember that data frames can be treated as matrices)
- MARGIN – 1 for by row, 2 for by column
- FUN – name of function to apply (notice no ()s)
Other arguments can be provided, for example na.rm = T if the function applied takes the na.rm = argument (e.g., mean()).
The function takes the matrix provided to the X = argument and applies the function passed to FUN = along the margin (rows/columns) of the matrix, specified by the MARGIN = argument.
This is useful, don’t you think? The function becomes even more useful when you realise you can apply your own functions (more on writing functions later). Let’s say, we want to know the standard error estimate based on the 5 values for each participant:
# define function (std error = sd / sqrt(n))
std.error <- function(x, na.rm) sd(x, na.rm = na.rm)/sqrt(length(na.omit(x)))
apply(df[ , 2:6], 1, std.error, na.rm = T) # na.rm value will get passed on to std.error
[1] 0.45907232 0.51924566 0.25257024 0.09520509 0.54448981 0.27761695
[7] 0.20968795 0.28694736 0.26581403 0.44425228 0.33198857 0.24756659
[13] 0.32928144 0.18831305 0.19465280 0.26165074 0.58132589 0.32404826
[19] 0.58314065 0.36387481You don’t even have to create a function object!
# same thing, different way
apply(df[ , 2:6], 1,
function(x) sd(x, na.rm = T)/sqrt(length(na.omit(x))))
[1] 0.45907232 0.51924566 0.25257024 0.09520509 0.54448981 0.27761695
[7] 0.20968795 0.28694736 0.26581403 0.44425228 0.33198857 0.24756659
[13] 0.32928144 0.18831305 0.19465280 0.26165074 0.58132589 0.32404826
[19] 0.58314065 0.36387481To give another example, this is how you can calculate the standard deviation of each of the X columns of df.
apply(df[ , 2:6], 2, sd, na.rm = T)
X1 X2 X3 X4 X5
0.7944870 0.8368392 0.6341497 0.7923571 0.9171290 There are quite a few functions in the apply() family (e.g., vapply(), tapply(), mapply(), sapply()), each doing something slightly different and each appropriate for a different data structure (vector, matrix, list, data.frame) and different task.
You can read about all of them, if you want but we’d like to tell you about one in particular – lapply()
The lapply() function takes a list (list apply) and applies a function to each of its elements.
The function returns a list.
This function is useful because data frames can also be treated as lists.
This is what you do every time you use the $ operator.
So, to do Task 1 using lapply(), you can simply do:
lapply(df[ , 2:6], sd, na.rm = T)
$X1
[1] 0.794487
$X2
[1] 0.8368392
$X3
[1] 0.6341497
$X4
[1] 0.7923571
$X5
[1] 0.917129If you don’t want the output to be a list, just use unlist():
Say we want to round all the X columns to 2 decimal places.
That means, that we want to assign to columns 2-6 of df values corresponding to rounded versions of the same columns:
So these are the two most useful functions from the apply() family you should know.
As a general tip, you can use apply() for by-row operations and lapply() for by-column operations on data frames.
The nice thing about these function is that they help you avoid repetitive code.
For instance, you can now turn several columns of your data set into factors using something like df[ , c(2, 5, 7, 8)] <- lapply(df[ , c(2, 5, 7, 8)], factor).
Cool, innit?
Conditional code evaluation
if
The idea is pretty simple – sometimes you want some code to run under certain circumstances but not under others. This is what conditional code evaluation is for and this is what it looks like:
if (condition) {
code
}
The (not actual) code above is how you tell R to run whatever code if and only if the condition is met.
It then follows that whatever the condition is, it must evaluate to a single boolean (TRUE/FALSE):
If we change cond to FALSE, the code in the curly braces will be skipped:
Pretty straight-forward, right?
OK, now, the condition can be whatever logical operation that returns a single boolean, not just TRUE or FALSE.
Here’s an example of something more useful:
Here, the x vector is checked for NA values using is.na().
The function, however, returns one boolean per element of x and not just a single T/F.
The any() function checks the returned vector of logicals and if there are any Ts, returns TRUE and if not, returns FALSE.
It might also be reasonable to have different chunks of code you want to run, one if condition is met, the other if it isn’t.
You could do it with multiple if statements:
It is a bit cumbersome though, don’t you think?
else
Luckily, there’s a better way of doing the same thing – the else statement:
Here, if the any(is.na(x)) condition evaluates to TRUE, the first line of code is run and the second one is skipped.
If it’s FALSE, the code in the else clause will be the one that gets run.
So, if there are only two outcomes of the test inside the condition clause that we want to run contingent code for, if () {} else {} is the syntax to use.
Bear in mind, however, that sometimes, there might be more than two meaningful outcomes.
Look at the following example:
else if
You should now be able to understand the following code without much help:
x <- "green"
if (x == "blue") {
print(paste("Her eyes were", x))
} else if (x == "brown") {
print(paste("As is the case with most people, her eyes were", x))
} else if (x %in% c("green", "grey")) {
print(paste("She was one of those rare people whose eyes were", x))
}
print("Next line of code...")
[1] "She was one of those rare people whose eyes were green"
[1] "Next line of code..."If you feel like it, you can put the code above inside a for loop, assigning x values of "blue", "brown", "grey", "green", and – let’s say – "long", one at a time and see the output.
for (x in c("blue", "brown", "grey", "green", "long")) {
if (x == "blue") {
print(paste("Her eyes were", x))
} else if (x == "brown") {
print(paste("As is the case with most people, her eyes were", x))
} else if (x %in% c("green", "grey")) {
print(paste("She was one of those rare people whose eyes were", x))
}
print("Next line of code...")
}
[1] "Her eyes were blue"
[1] "Next line of code..."
[1] "As is the case with most people, her eyes were brown"
[1] "Next line of code..."
[1] "She was one of those rare people whose eyes were grey"
[1] "Next line of code..."
[1] "She was one of those rare people whose eyes were green"
[1] "Next line of code..."
[1] "Next line of code..."The point the example above is aiming to get across is that, when using else, you need to make sure that the code after the clause is appropriate for all all possible scenarios, where the condition in if is FALSE.
ifelse()
In situations, where you are happy that there are indeed only two sets of outcomes of your condition, you can use the shorthand function ifelse().
Take a look at the following code example:
apples <- data.frame(
colour = c("green", "green", "red", "red", "green"),
taste = c(4.3, 3.5, 3.9, 2.7, 6.4)
)
apples$redness <- ifelse(apples$colour == "red", 1, 0)
apples$redness
[1] 0 0 1 1 0What is happening here? In this command, a new variable is being created in the apples data frame called redness.
To decide what value to give each case (row) for this variable, an ifelse statement is used.
For each row in the data, the value of the redness variable is based on the value of the colour variable.
When colour is red, the value for redness is 1, for any other value of colour - redness; will be 0.
ifelse() has the following general formulation:
ifelse(condition,
value to return if TRUE,
value to return if FALSE)As you might see, a nice advantage of ifelse() over if () {} else {} is that it is vectorised, meaning it will evaluate for every element of the vector in condition.
On the flip side, ifelse() can only return a single object, while the code inside if () {} else {} can be arbitrarily long and complex.
For that reason, ifelse() is best for simple conditional assignment (e.g., x <- ifelse(...)), while if () {} else {} is used for more complex conditional branching of your code.
As with many other things in programming (and statistics), it’s a case of horses for courses…
To consolidate this, let’s look at the data frame again:
head(apples)
colour taste redness
1 green 4.3 0
2 green 3.5 0
3 red 3.9 1
4 red 2.7 1
5 green 6.4 0For the first two rows, the condition evaluates to FALSE because the first two values in the colour variable are not "red".
Therefore, the first two elements of our outcome (the new variable redness) are set to 0.
The next two values in the colour variable were "red" so, for these elements, the condition evaluated to TRUE and thus the next two values of redness were set to 1.
Nesting clauses
The level of conditional evaluation shown above should give you the necessary tools for most conditional tasks.
However, if you’re one of those people who like to do really complicated things, then a) what are you doing with your life? and b) bear in mind if, else, and ifelse() can be combined and nested to an arbitrary level of complexity:
# not actual code!
if (cond_1) {
if (cond_1_1) {
...
} else if (cond_1_2) {
...
} else {
x <- ifelse(cond_1_3_1, ..., ...)
}
} else (cond_2) {
x <- ifelse(cond_2_1,
ifelse(cond_2_1_1, ..., ...),
...)
} ...Same rules apply. If you’re brave (or foolhardy) enough to get into this kind of programming, then please make sure all your opening and closing brackets and curly braces are paired up in the right place, otherwise fixing your code will be a right bag of giggles!
Writing your own functions
Admittedly, this section about user-defined functions is a little bit advanced. However, the ability to write your own functions is an immensely powerful tool for data processing and analysis so you are encouraged to put some effort into understanding how functions work and how you can write your own. It’s really not difficult!
Functions are objects too!
It’s probably getting a bit old at this stage but everything in R is an object.
And since functions are a subset of everything, they also are objects.
They are essentially chunks of code stored into a named object that sits in some environment.
User-defined functions will be located in the global environment, while functions from packages (either pre-loaded ones or those you load using library()) sit in the environments of their respective packages.
If you want to see the code inside a function, just type it into the console without the brackets and press Enter. You might remember this chap:
lower.tri
function (x, diag = FALSE)
{
d <- dim(x)
if (length(d) != 2L)
d <- dim(as.matrix(x))
if (diag)
.row(d) >= .col(d)
else .row(d) > .col(d)
}
<bytecode: 0x00000000260871f8>
<environment: namespace:base>Anatomy of a function
Looking at the code above you can see the basic structure of a function:
- First, it’s specified that this object is a
function - Second, in the
()s, there’s the specifications of the argument the function takes including any default values- As you can see
lower.tri()takes two arguments,xanddiag, the latter of which is set by default toFALSE
- As you can see
- Third, there is the body of the function enveloped in a set of curly braces
{}which includes the actual code that does the function’s magic - Finally, there is some meta-information including the environment in which the function lives (in this case, it’s the
"base"package)
Notice that the function code only works using the x and diag objects.
No matter what you pass to the function’s x argument will – as far as the function is concerned – be called x.
That is why R doesn’t know where the value passed to the arguments of functions come from!
DIY
To make your own function, all you need to do is follow the syntax above, come up with your own code, and assign the function object to a name in your global R environment:
my_fun <- function(arg1, arg2, arg3, ...) {
some code using args
return(object to return)
}The return() function is not strictly speaking necessary but it’s good practice to be explicit about this of the many potential objects inside of the function’s environment you want to return to the global environment.
Let’s start with something simple. Let’s write a function that takes as its only argument a person’s name and returns a greeting:
So, we created a named object hello and assigned it a function of one argument name =.
Inside the {}s, there is code that creates and object out with a character string created from pasting together "Hello ", whatever gets passed to the name = argument, and an exclamation point.
Finally, this out gets returned into the global environment.
Let’s see if it works:
hello("Tim")
[1] "Hello Tim!"Nice. Not extremely useful, but nice…
Let’s create a handier function. One thing that is sometimes done when cleaning data is removing outlying values. Wouldn’t it be useful to have a function that does it for us? (Aye, it would!)
Basic boxplots are quite a good way of identifying outliers. Let’s demonstrate this:
OK, as the boxplot clearly shows, there’s a few outlying values in the x variable.
As you now surely know, everything in R is an object and so we can look at the object returned by boxplot() to see if we can use it to identify which element in x is the culprits:
The str() function shows us the structure of the boxplot() output object.
On inspection, you can see that the $out element of the list returned by the function includes the outlying values.
The one we imputed manually (15.82) is there, which is a good sanity check.
Let’s extract only these values:
outl <- boxplot(x, plot = F)$out # don't show plot
outl
[1] 15.820000 -2.740971Cool, all we need to do now is replace the values of x that are equal to these values with NAs:
x %in% outl
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[11] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[21] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[31] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[41] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[51] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[71] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[81] FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
[91] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEx[x %in% outl] <- NA
We can now look at x to see that the outlying values have been replaced with NAs:
x
[1] 0.151632788 1.097776244 0.664274729 0.787125530 -0.872618372
[6] -0.051169176 -1.725807496 0.769506359 -0.513882319 1.300058018
[11] -0.354740362 0.039929516 0.828109714 2.347927522 -1.652985393
[16] -0.635121125 -0.512907704 -0.173740135 -0.358684436 0.476645368
[21] -0.089425361 0.367969219 0.365033848 -2.023814744 0.145554644
[26] 1.804865688 1.066488428 -1.493169014 -0.595923470 1.072180459
[31] 1.133003147 0.175172282 0.064704260 0.797494580 -1.548467661
[36] -1.199822335 0.267611746 0.758822712 1.399539052 1.116901888
[41] 0.295025478 0.278192492 -0.972389445 0.396184426 1.597048018
[46] 0.373437954 -1.176761040 0.856991705 0.714098678 -0.547020112
[51] 0.013395797 -0.323134889 0.679921544 -0.403409317 0.027522412
[56] 0.393855398 -1.502504606 -0.423392348 0.005243667 1.225821843
[61] 0.034879167 -0.088373564 0.357826998 -0.814470637 0.210361089
[66] -0.495406869 -0.315182455 0.615313894 0.769988127 0.193253835
[71] 1.027889034 0.445830050 -1.129798416 1.217170780 0.519427429
[76] -0.734993730 0.756610139 0.851936267 1.605322748 -0.440291756
[81] -1.035255545 NA 0.129056684 0.885961938 1.740494816
[86] -0.632292780 -0.122075112 NA -0.919321206 0.649698629
[91] 0.671570570 -1.069723314 0.333325254 -0.983005709 0.976081753
[96] 0.438362131 0.740508906 -0.690093792 1.053573628 0.175872256Greatow that we know our algorithm for removing outliers, we can write our function:
Let’s try it out!
x <- rnorm(20, 9, 2)
x[2] <- 1520
x
[1] 6.717492 1520.000000 11.677285 9.690379 10.510965
[6] 7.758933 10.452724 8.273896 9.042303 10.284755
[11] 8.808526 10.810477 9.299854 9.371841 8.161094
[16] 12.510791 8.399752 11.984442 7.083689 8.070372x <- out.liar(x)
x
[1] 6.717492 NA 11.677285 9.690379 10.510965 7.758933
[7] 10.452724 8.273896 9.042303 10.284755 8.808526 10.810477
[13] 9.299854 9.371841 8.161094 12.510791 8.399752 11.984442
[19] 7.083689 8.070372Pretty neat, huh?
The code inside of the function definition can be as simple or as complicated as you want it to be.
However, it must run without errors and you need to think about various edge cases that might break the code or lead to unexpected behaviour.
For instance, if we give out out.liar() function a character vector, it will throw an error because boxplot() can only cope with numeric vectors:
out.liar(letters)
Error in x[floor(d)] + x[ceiling(d)]: non-numeric argument to binary operatorThis error message is a little obscure but what happened is that out.liar() passed the vector of letters to boxplot() which, in turn, passed it to the + function.
Since you cannot add letters, the function threw an error, thus breaking boxplot() and out.liar().
You might also wish to make the function able to identify outliers in a data frame. To do that you would have to make the function recognise which columns of the data frame provided are numeric and then run the code on each one of these columns. Finally the function should return the entire data frame with the non-numeric columns untouched and the numeric ones modified:
out.liar <- function(variable) { # arguments can be called whatever
if (class(variable) == "data.frame") {
# identify numeric variables by applying the is.numeric
# function to each column of the data frame
num_vars <- unlist(lapply(variable, is.numeric))
# run the out.liar function on each numeric column
# this kind of recurrence where you run a function inside of itself
# is allowed and often used!
variable[num_vars] <- lapply(variable[num_vars], out.liar)
} else {
remove <- boxplot(variable, plot = F)$out
variable[variable %in% remove] <- NA
}
return(variable)
}
Let’s see if it works. First, create some data frame with a couple of outlying values:
df <- data.frame(id = factor(1:10), var1 = c(100, rnorm(9)),
var2 = c(rchisq(9, 4), 100), var3 = LETTERS[1:10])
df
id var1 var2 var3
1 1 100.0000000 2.630146 A
2 2 0.9331203 11.296622 B
3 3 -1.1495676 3.159593 C
4 4 1.2121541 1.346752 D
5 5 -1.7792191 11.644517 E
6 6 0.1948948 3.050007 F
7 7 2.2206436 0.732933 G
8 8 0.2011317 5.301940 H
9 9 -0.5588346 1.441614 I
10 10 -1.4433049 100.000000 JNext, feed df to out.liar():
out.liar(df)
id var1 var2 var3
1 1 NA 2.630146 A
2 2 0.9331203 11.296622 B
3 3 -1.1495676 3.159593 C
4 4 1.2121541 1.346752 D
5 5 -1.7792191 11.644517 E
6 6 0.1948948 3.050007 F
7 7 2.2206436 0.732933 G
8 8 0.2011317 5.301940 H
9 9 -0.5588346 1.441614 I
10 10 -1.4433049 NA JFinally, check if the function still works on single columns even after our modification:
x <- rnorm(20, 9, 2)
x[2] <- 1520
out.liar(x)
[1] 7.930573 NA 10.284230 11.337346 10.069270 9.698254
[7] 7.763529 9.878834 9.708315 NA 6.743655 7.445690
[13] 10.101995 10.016954 8.461315 9.917722 9.071775 11.057335
[19] 8.426894 9.347640Everything looking good!
So this is how you write functions. The principle is simple but actually creating good and safe functions requires a lot of thinking and attention to detail.
Hacking
Finally, if you’re really into the nitty-gritty of R, a great way of learning how to write functions is to look at ones you use and try to pick them apart, break them, fix them, and put them back together.
Since – sing along – everything in R is an object, you can assign the code inside of an already existing function to some other object.
For instance, the boxplot() function calls a different “method” based on what input you give it (this is rather advanced programming so don’t worry too much about it!).
The one we used is called botplot.default() and it hides deep inside package "graphics".
To get it out, we need to tell R to get it from there using the package:::function syntax:
box2 <- graphics:::boxplot.default
box2
function (x, ..., range = 1.5, width = NULL, varwidth = FALSE,
notch = FALSE, outline = TRUE, names, plot = TRUE, border = par("fg"),
col = "lightgray", log = "", pars = list(boxwex = 0.8, staplewex = 0.5,
outwex = 0.5), ann = !add, horizontal = FALSE, add = FALSE,
at = NULL)
{
args <- list(x, ...)
namedargs <- if (!is.null(attributes(args)$names))
attributes(args)$names != ""
else rep_len(FALSE, length(args))
groups <- if (is.list(x))
x
else args[!namedargs]
if (0L == (n <- length(groups)))
stop("invalid first argument")
if (length(class(groups)))
groups <- unclass(groups)
if (!missing(names))
attr(groups, "names") <- names
else {
if (is.null(attr(groups, "names")))
attr(groups, "names") <- 1L:n
names <- attr(groups, "names")
}
cls <- lapply(groups, class)
cl <- NULL
if (all(vapply(groups, function(e) {
is.numeric(unclass(e)) && identical(names(attributes(e)),
"class")
}, NA)) && (length(unique(cls)) == 1L))
cl <- cls[[1L]]
for (i in 1L:n) groups[i] <- list(boxplot.stats(unclass(groups[[i]]),
range))
stats <- matrix(0, nrow = 5L, ncol = n)
conf <- matrix(0, nrow = 2L, ncol = n)
ng <- out <- group <- numeric(0L)
ct <- 1
for (i in groups) {
stats[, ct] <- i$stats
conf[, ct] <- i$conf
ng <- c(ng, i$n)
if ((lo <- length(i$out))) {
out <- c(out, i$out)
group <- c(group, rep.int(ct, lo))
}
ct <- ct + 1
}
if (length(cl) && cl != "numeric")
oldClass(stats) <- oldClass(conf) <- oldClass(out) <- cl
z <- list(stats = stats, n = ng, conf = conf, out = out,
group = group, names = names)
if (plot) {
if (is.null(pars$boxfill) && is.null(args$boxfill))
pars$boxfill <- col
do.call(bxp, c(list(z, notch = notch, width = width,
varwidth = varwidth, log = log, border = border,
pars = pars, outline = outline, horizontal = horizontal,
add = add, ann = ann, at = at), args[namedargs]),
quote = TRUE)
invisible(z)
}
else z
}
<bytecode: 0x000000001e65d198>
<environment: namespace:graphics>This is the code that creates the boxplot and, if you wish, you can try to look into it and find how the function identifies outliers.
You can even change the function by typing edit(box2).
Being able to peer under the hood of readymade functions opens up an infinite playground for you so enjoy yourself!
Reshaping Data
Data have a nasty habit of coming to us in a rather messy state, meaning that they do not conform to the three principles of tidy data:
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
This is what tidy data look like in practice:
Error in kable_styling(.): could not find function "kable_styling"But more often than not, we get something delightful, such as:
Error in kable_styling(.): could not find function "kable_styling"As you can see, this format breaks the first 2 rules of tidy data: Each of the condition... columns contains several pieces of information about the values in the given column and there are multiple observations of the same variable ("rating" in the tidy format) per row.
That is really not optimal.
Luckily R, and more specifically the tidyverse, provides tools to (relatively) easily turn messy data into tidy data.
Relatively, because data can sometimes be so messy that it just takes a while and a bit of effort to get it in shape.
Rest assured, however, that the difference in time and effort between tidying data in R on the one hand and Excel or SPSS on the other is exponential.
The example above is not too horrendous but let’s start with something easier anyway.
If you want to follow along, here is the code that creates the messy data:
Setting random seed with set.seed() ensures you will get the same “randomly” generated numbers from the rnorm() (random normal) functions.
Tidyverse
As the name suggests, tidyverse is a bit of a parallel universe to base R.
It is still R and all the functions tidyverse encompasses can be used the “normal” way but they come to their full strength when used with the tidyverse syntax.
So yes, tidyverse is still the R language but it’s a dialect within the language that’s somewhat different to base R.
The main difference between base R and tidyverse is that while the former reads “inside-out”, the latter presents a pipeline of operations that flows from left to right.
What do we mean by “inside-out”
Let’s look at this base R code:
Here, we generated 100 random standard normal numbers, took their mean, and rounded it to 3 decimal places. The first function is the innermost one and the sequence proceed outwards. Here is the same thing written the tidyverse way:
Here, the sequence goes from left to right.
The pipe operator %>% takes the output of whatever is to the left of it and pushes it to the function to the right of it as its first argument.
rnorm(100) %>% mean() is thus the same as mean(rnorm(100)).
So we first took the output of rnorm(100) and pushed it to the mean() function as its first argument.
Then took the output of this step and pushed it to the round() function, again as its first argument, and, as we wanted to round to 3 decimal places, we specified the second argument of round() to be 3.
Pipes are quite useful when your manipulation of a single object involves a sequence of several steps where none of the intermediate steps is particularly useful to you.
They make the code legible in a way that many find more intuitive than the inside-out way base R works.
Apart from this principle, tidyverse includes several packages that were written with a uniform approach to data processing and visualisation in mind.
Some of these packages are ggplot2, tidyr, dplyr, tibble.
The latter introduces an additional data structure called tibble that is a kind of data.frame+ and the former presents an alternative approach to graphics in R.
You can install the entire suite as a single package, aptly named "tidyverse" using the install.packages("tidyverse") command.
Just remember you also need to load the package if you want to use the functions therein! (for more information, see the tidyverse website)
“Wide to long”
OK, first of all, let’s simplify the data. Let’s just say we only have a single condition with two observations per participant:
df_simple <- df_mess %>%
dplyr::select(-contains("B")) %>% # get rid of columns containing B in their name
rename(time_1 = conditionA_1, time_2 = conditionA_2) # rename "condition..." variables to "time_"
And here’s what we get when we print out df_simple.
Error in kable_styling(.): could not find function "kable_styling"
What we want here is a data set in the long format with rows in columns id and age duplicated for each time.
We also want an identifying time column with values 1 and 2 and a single rating column with the observations.
We want this:
Error in kable_styling(.): could not find function "kable_styling"
You won’t be surprised to find out that there are multiple ways to do this.
In fact, there are multiple tidyverse ways tooet’s then try to be down with them kids and talk about the latest (as of Jan 2020) way – the pivot_longer() function from the tidyr package that comes as part of tidyverse.
In its minimal form, the pivot_longer() function requires 4 arguments:
data=, if we’re using the%>%pipe, this gets taken care ofcols=, columns we want to work with, the rest will get duplicated as needednames_to=, name of the variable we want to construct from names of columns incols=values_to=, name of the variable we want to construct from values incols=
Let’s try the minimal example to see what the function does:
df_simple %>%
pivot_longer(cols = c("time_1", "time_2"),
names_to = "time",
values_to = "rating") %>%
head(10) # only show first 10 rows to save space
# A tibble: 10 x 4
id age time rating
<int> <dbl> <chr> <dbl>
1 1 21 time_1 8
2 1 21 time_2 9
3 2 26 time_1 7
4 2 26 time_2 11
5 3 28 time_1 6
6 3 28 time_2 8
7 4 18 time_1 6
8 4 18 time_2 7
9 5 26 time_1 5
10 5 26 time_2 8
So we took the time_1 and time_2 columns and transformed them into a time and rating columns.
The values in the other variables (i.e., id and age) got duplicated as appropriate.
The result is, however, not quite what we wanted.
To turn the time variable into something more workable, we could use any one of several functions R provides for recoding variables or string replacement.
We can also use the additional names_prefix= argument of pivot_longer() to tell R that the "time_" string is merely a prefix and does not contain information about the value.
And while we’re at it, we can change the cumbersome c("time_1", "time_2") to contains("time").
This way, we can have an arbitrary number of time_ columns and not worry about typing them all out:
df_simple %>%
pivot_longer(cols = contains("time"),
names_to = "time", names_prefix = "time_",
values_to = "rating") %>%
head(10)
# A tibble: 10 x 4
id age time rating
<int> <dbl> <chr> <dbl>
1 1 21 1 8
2 1 21 2 9
3 2 26 1 7
4 2 26 2 11
5 3 28 1 6
6 3 28 2 8
7 4 18 1 6
8 4 18 2 7
9 5 26 1 5
10 5 26 2 8One last thing: As you can see the class of the time column is "character" (<chr>).
We can use the names_transform= argument to change it (and any other column) to something else, say "integer".
The argument requires a list containing a name = function pairs of variables we want to manipulate:
df_long <- df_simple %>%
pivot_longer(cols = contains("time"),
names_to = "time",
names_prefix = "time_",
values_to = "rating",
names_transform = list(
time = as.integer
))
head(df_long, 10)
# A tibble: 10 x 4
id age time rating
<int> <dbl> <int> <dbl>
1 1 21 1 8
2 1 21 2 9
3 2 26 1 7
4 2 26 2 11
5 3 28 1 6
6 3 28 2 8
7 4 18 1 6
8 4 18 2 7
9 5 26 1 5
10 5 26 2 8Great, the variable is not of class "numeric" (type "double"):
If this is a little confusing, just know that there are two types of numeric variables: integer and double.
An integer can only hold a whole number, while a double can have a number of decimal places.
It is called double because it requires twice as much computer memory to be stored (same number of digits on either side of the decimal point).
So if you can be absolutely certain that your variable will only ever include integers and if you care about memory (i.e., you have really big datasets), it may be better to use as.integer rather than as.numeric (no brackets here after function name!).
So yeah, that’s the basic wide-to-long transformation in R.
But what if our data are a bit messier, just like our original data set:
Error in kable_styling(.): could not find function "kable_styling"
Here, we’re in a situation where we need to combine four columns of values into one but we also need two identifier variables, one for condition and one for measurement occasion.
If we have a look at the documentation to the function by typing ?pivot_wider, in the Arguments section we can read that
names_toCan be a character vector, creating multiple columns, ifnames_sepornames_patternis provided.
This means that we can pass c("condition", "time") to the names_to= argument but if we do that, we have to specify one of the two arguments mentioned above.
As the names_sep= argument is both appropriate for our data and easier to explain, let’s work with that.
All we need to do is tell R what character separates condition from measurement occasion.
In our case, this is the underscore, “_“:
df_mess %>%
pivot_longer(cols = starts_with("cond"),
names_to = c("condition", "time"),
names_sep = "_",
values_to = "rating") %>%
head(10)
# A tibble: 10 x 5
id age condition time rating
<int> <dbl> <chr> <chr> <dbl>
1 1 21 conditionA 1 8
2 1 21 conditionA 2 9
3 1 21 conditionB 1 7
4 1 21 conditionB 2 6
5 2 26 conditionA 1 7
6 2 26 conditionA 2 11
7 2 26 conditionB 1 7
8 2 26 conditionB 2 5
9 3 28 conditionA 1 6
10 3 28 conditionA 2 8Cool, we basically got what we wanted: two identifier variables and a single value variable.
From here, we can just repeat what we did in our previous example.
First, let’s get rid of the “condition” prefix using the names_prefix= argument:
df_mess %>%
pivot_longer(cols = starts_with("cond"),
names_to = c("condition", "time"),
names_sep = "_",
names_prefix = "condition",
values_to = "rating") %>% head(10)
# A tibble: 10 x 5
id age condition time rating
<int> <dbl> <chr> <chr> <dbl>
1 1 21 A 1 8
2 1 21 A 2 9
3 1 21 B 1 7
4 1 21 B 2 6
5 2 26 A 1 7
6 2 26 A 2 11
7 2 26 B 1 7
8 2 26 B 2 5
9 3 28 A 1 6
10 3 28 A 2 8And second, let’s use the names_transform= argument to set appropriate classes to our variables.
Instead of just printing out the result, let’s save it into df_long:
df_long <- df_mess %>%
pivot_longer(cols = starts_with("cond"),
names_to = c("condition", "time"),
names_sep = "_",
names_prefix = "condition",
values_to = "rating",
names_transform = list(
id = as.factor,
age = as.integer,
condition = as.factor,
time = as.integer,
rating = as.integer
))
head(df_long, 10)
# A tibble: 10 x 5
id age condition time rating
<int> <dbl> <fct> <int> <dbl>
1 1 21 A 1 8
2 1 21 A 2 9
3 1 21 B 1 7
4 1 21 B 2 6
5 2 26 A 1 7
6 2 26 A 2 11
7 2 26 B 1 7
8 2 26 B 2 5
9 3 28 A 1 6
10 3 28 A 2 8
Et voilà!
Just in case you are wondering about the names_pattern= argument, let’s very briefly talk about it.
It is great but it is not trivially easy to use.
The reason for that is that it uses so called “regular expressions” (or regex).
This is a very powerful tool for manipulating strings.
It can be used with many R functions, one of which is general string substitugion gsub().
Let’s see…
Whistle-stop tour of Regex
Imagine we have these six character strings:
x <- c("conditionA_1", "conditionA_2", "condition_Atime_1", "A_1", "conditionA_time1", "conditionA_12")
x
[1] "conditionA_1" "conditionA_2" "condition_Atime_1"
[4] "A_1" "conditionA_time1" "conditionA_12" Our task is to only exatract the capital lettr and the number.
This is what gsub() is for.
It can substitute any part of a string for any string (including empty string, "").
s <- "I love R"
s
[1] "I love R"# replace "love" with "feel ..." in object s
s <- gsub("love", "feel very much meh about", s)
s
[1] "I feel very much meh about R"We can use gsub() to get rid of "condition" from our x:
gsub("condition", "", x)
[1] "A_1" "A_2" "_Atime_1" "A_1" "A_time1" "A_12" OK, the examples above do not involve any regex. They simply use strings to replace strings. What regex allows us to do is provide more general patterns for string extraction/replacement.
x
[1] "conditionA_1" "conditionA_2" "condition_Atime_1"
[4] "A_1" "conditionA_time1" "conditionA_12" gsub("[a-z]*_?(.).*?(\\d+)", "\\1 \\2", x)
[1] "A 1" "A 2" "A 1" "A 1" "A 1" "A 12"This is of course not intelligible at all if you don’t understand regex. Explaining what the two weird strings mean is not the purpose of this section. Basically, it is saying:
“There will be some number of characters from small a to small z (including none!), then there might be a _. After that, remember the next single character, whatever it is. Then, there will be an arbitrary number of other non-digit characters after which remember one or more digits. Got it? OK then, only keep the two things I asked you to remember separated by a space. Thank you!”
You are not expected to understand this. The point is to show you that, as long as there is some discernible pattern in your strings, you can use regex to extract the relevant bits.
This is all very nice but how can we use it in pivot_longer()?
Well, let’s go back to our original variable names:
names(df_mess)
[1] "id" "age" "conditionA_1" "conditionA_2"
[5] "conditionB_1" "conditionB_2"Our pattern here can, for instance, be “the word condition, then a single character to remember, followed by an underscore and, finally a single character to remember.” In regex this translates to:
We could make the pattern more specific or more general but this does the job well (it also kinda looks cute with its googly eyes).
So let’s just feed the pattern to the names_patter= argument of pivot_longer():
df_mess %>%
pivot_longer(cols = starts_with("cond"),
names_to = c("condition", "time"),
names_pattern = "condition(.)_(.)",
values_to = "rating") %>%
head(10)
# A tibble: 10 x 5
id age condition time rating
<int> <dbl> <chr> <chr> <dbl>
1 1 21 A 1 8
2 1 21 A 2 9
3 1 21 B 1 7
4 1 21 B 2 6
5 2 26 A 1 7
6 2 26 A 2 11
7 2 26 B 1 7
8 2 26 B 2 5
9 3 28 A 1 6
10 3 28 A 2 8Because we gave two column names to the names_to= argument, the function knows that whatever is in the first set of brackets in names_patter= belongs in the first column ("condition") and the stuff in the second set of brackets belongs in the second column ("time").
And thus we don’t need the names_prefix= or names_sep= arguments at all.
Cool, isn’t it?
Now that our data are tidy, we can – for instance – run a mixed-effect model analysing the effect of condition×time on rating:
Analysis of Variance Table
npar Sum Sq Mean Sq F value
condition 1 16.133 16.133 11.9151
time 1 4.033 4.033 2.9788
condition:time 1 56.033 56.033 41.3829summary(m1)
Linear mixed model fit by REML ['lmerMod']
Formula: rating ~ condition * time + (1 | id)
Data: df_long
REML criterion at convergence: 389.3
Scaled residuals:
Min 1Q Median 3Q Max
-2.6233 -0.4833 -0.1575 0.5043 2.3942
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 0.1615 0.4019
Residual 1.3540 1.1636
Number of obs: 120, groups: id, 30
Fixed effects:
Estimate Std. Error t value
(Intercept) 4.7667 0.4807 9.916
conditionB 3.3667 0.6718 5.011
time 1.7333 0.3004 5.769
conditionB:time -2.7333 0.4249 -6.433
Correlation of Fixed Effects:
(Intr) cndtnB time
conditionB -0.699
time -0.938 0.671
conditnB:tm 0.663 -0.949 -0.707This neatly demonstrates an important point when working with R - Once the data are in shape, fitting the right model is a piece of cake!
There is quite a bit more that the pivot_longer() function and its pivot_wider() counterpart can do.
If you want to read up on this, check out this post
Descriptives in tidyverse
Another neat feature of tidyverse is its arsenal of functions for data description and summary statistics by groups.
The logic is pretty straightforward and it chimes with the overarching philosophy of tidyverse pipelines.
Two functions in particular are very useful and work very well together: group_by() %>% summarise().
group_by is pretty self-explanatory – it groups the data by levels of a given variable or combinations of variables.
On its own it doesn’t do anything else and its action is not even visible but using it is the first step to getting descriptive statistics by factor(s).
summarise() should follow group_by in the pipeline.
It is used to create summary data frame (well, actually a tibble) with specified variables.
For instance, if we want get the mean rating per each time point from our long-format df from the beginning of this lab sheet, we would just push it into %>% group_by(time) %>% summarise(mean_rating = mean(rating)).
We can even create several summary variables, each with its own statistic.
We don’t even need df to be in the long format.
Instead, we can just extend our pipeline from earlier on like this:
df_long %>%
group_by(time) %>%
summarise(n = n(),
mean_rating = mean(rating))
# A tibble: 2 x 3
time n mean_rating
<int> <int> <dbl>
1 1 60 6.82
2 2 60 7.18
Pretty neat, huh?
As mentioned above, the output is a tibble (augmented data frame) and can be kept for later by storing it in an R object.
Objects like the one you’ve just created can be used for creating pretty fancy plots.
Data visualisation
One of R’s main strengths is undoubtedly its wide arsenal of data visualisation functions.
There are multiple packages dedicated to all sorts of visualisation techniques, from basic plots, to complex graphs, maps, and animations.
Arguably the most popular package in psychology and data science is ggplot2 (gg stands for “grammar of graphics”) we’ve already briefly mentioned.
It is a part of the tidyverse suite so once you’ve installed and loaded that, you don’t need to worry about ggplot2.
qplot()
ggplot2 provides two main plotting functions: qplot() for quick plots useful for data exploration and ggplot() for fully customisable publication-quality plots.
Let’s first look at qplot()
This is basically a ggplot2 alternative to base R’s general purpose plotting function plot().
When you use it, it will try to guess what kind of plot you likely want based on the type of data you provide.
If we give it a single numeric vector (or column), we will get a histogram:
If we give it a categorical variable (character vector or factor), it will give us a bar chart:
x <- sample(LETTERS[1:4], 100, replace = T)
x
[1] "C" "A" "D" "D" "A" "C" "D" "D" "A" "C" "A" "C" "A" "A" "A" "A"
[17] "B" "D" "D" "D" "A" "B" "D" "D" "B" "C" "D" "B" "C" "D" "B" "B"
[33] "B" "C" "B" "B" "A" "D" "D" "C" "D" "D" "B" "C" "A" "D" "A" "C"
[49] "D" "C" "B" "A" "A" "B" "D" "A" "B" "B" "B" "D" "B" "C" "B" "A"
[65] "C" "A" "C" "A" "B" "C" "D" "C" "B" "A" "D" "D" "D" "A" "A" "D"
[81] "D" "B" "A" "D" "C" "B" "B" "C" "C" "C" "C" "A" "A" "D" "D" "A"
[97] "B" "B" "D" "C"qplot(x)
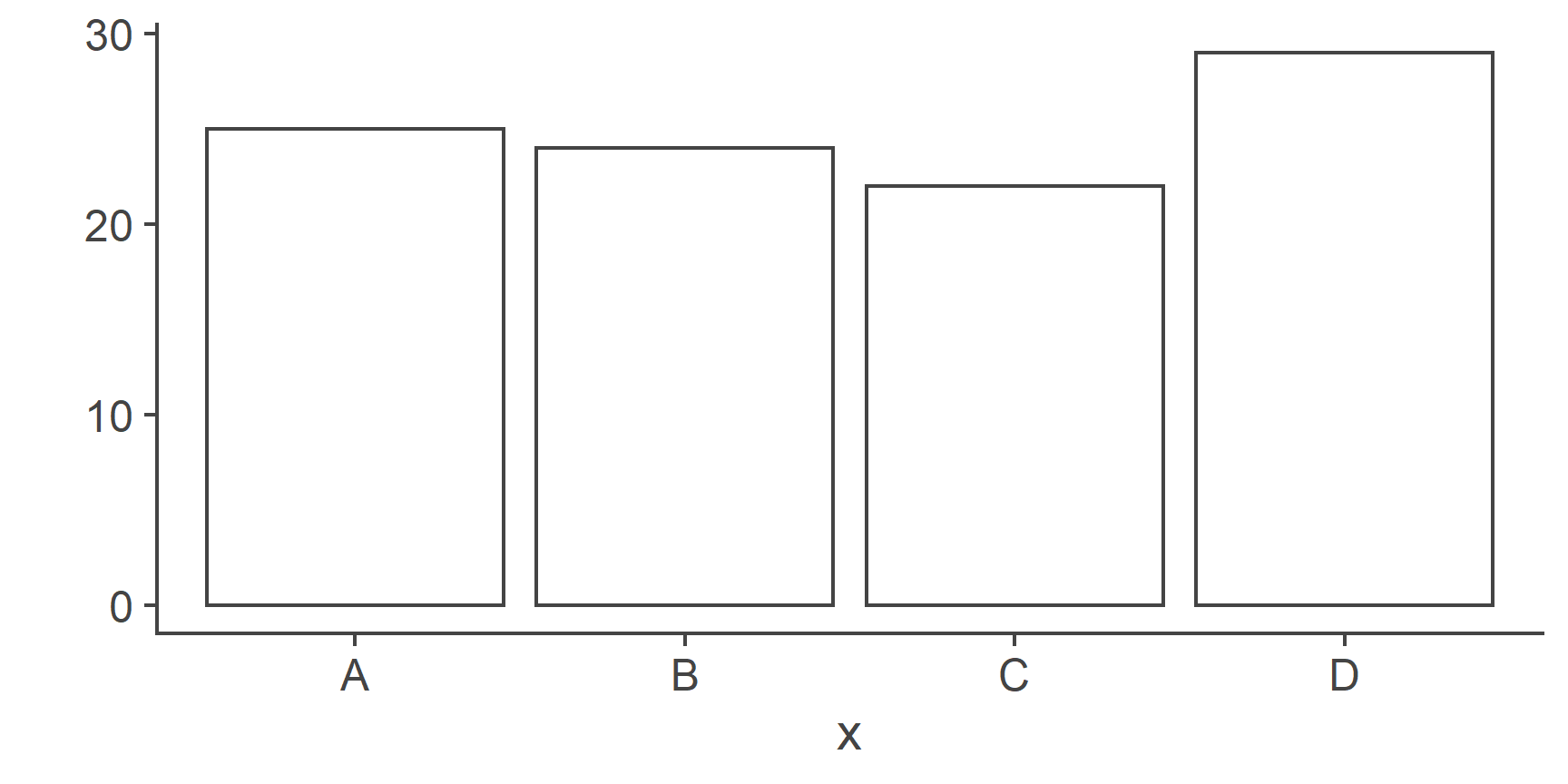
Two continuous variables will produce a scatterplot:
The function takes many arguments that can be used to customise the plots and select what type of plot to display (see ?qplot for details).
The geom = argument specifies which plotting element (geom) to use.
For instance, if we want a boxplot of a continuous variable by categorical variable, we can do:
qplot(x, y, geom = "boxplot")
We can specify several geoms in a single qplot.
For example, we may want to overlay a regression line over our scatterplot.
To do this, we need to tell qplot() to use both geom point and geom smooth.
Moreover, we want to specify that the method for the smoother (the function that draws the line) is the linear model “lm”.
(Try omitting the method = argument and see what happens)
You can actually do quite a bit more with just qplot() but the main workhorse of the package is the ggplot() function.
ggplot()
Unlike qplot(), plots with ggplot() are constructed in a layered fashion.
The bottom layer constructs the plotting space to which you then add layers of geoms, legends, axes, and what not.
Let’s use our df_long data set from earlier to illustrate this system of layers.
To refresh your memory, this is what the first 6 rows of the data set look like:
head(df_long)
# A tibble: 6 x 5
id age condition time rating
<int> <dbl> <fct> <int> <dbl>
1 1 21 A 1 8
2 1 21 A 2 9
3 1 21 B 1 7
4 1 21 B 2 6
5 2 26 A 1 7
6 2 26 A 2 11Let’s start with a simple histogram of the rating variable:
ggplot(df_long, aes(rating)) +
geom_histogram()
First, we used the ggplot() function to define the plotting space.
We told it to work with df_long and map the rating variable as the only “aesthetic”.
In ggplot2 jargon, any variable that’s supposed to be responsive to various plotting functions needs to be defined as an aesthetic, inside the aes() function.
The second layer tells ggplot() to add a histogram based on the variable in aes(), i.e., rating.
Similarly to qplot(), we can create a scatterplot by mapping 2 variables to aes() and choosing geom_point() as the second layer:
ggplot(df_long, aes(age, rating)) +
geom_point()
Do we want to change the colour, size, or shape of the points? No problem:
ggplot(df_long, aes(age, rating)) +
geom_point(colour = "blue", size = 4, pch = 2)
What if you want to colour the points by measurement time
To do this, we need to specify colour as an aesthetic mapping it to the desired variable:
ggplot(df_long, aes(age, rating)) +
geom_point(aes(colour = time))
Now, because time is a numeric variable, ggplot() thinks it makes most sense to create a continuous colour scale for different values of the variable.
However, that is not what we want: We only have two measurement occasions and so two distinct colours are much better.
To get what we want, we need to turn time into a factor:
df_long %>%
mutate(time = factor(time)) %>%
ggplot(aes(age, rating)) +
geom_point(aes(colour = time))
In this case, it doesn’t really matter if you put the individual aesthetics inside of the ggplot() or the geom_point() function.
The difference is that whatever you put into the topmost layer (ggplot()) will get passed on to all the subsequent geoms, while the aesthetic you give to a particular geom will only apply to it.
To illustrate this point, let’s add a regression line:
df_long %>%
mutate(time = factor(time)) %>%
ggplot(aes(age, rating)) +
geom_point(aes(colour = time)) + geom_smooth(method = "lm")
Since colour = time is given to geom_point(), it doesn’t impact geom_smooth() which only draws one line.
If we want geom_smooth to draw one line per time point, we can just move the colour = argument to the topmost ggplot() layer:
df_long %>%
mutate(time = factor(time)) %>%
ggplot(aes(age, rating, color = time)) +
geom_point() + geom_smooth(method = "lm")
Here is an example of a standard publication-ready grouped bar plot with error bars presenting a neat representation of a \(2\times 2\) design.
The data we’re plotting comes from the df_long data set we created at the bottom of the “Wide to long” section above.
Recall that the data set looks like this:
head(df_long)
# A tibble: 6 x 5
id age condition time rating
<int> <dbl> <fct> <int> <dbl>
1 1 21 A 1 8
2 1 21 A 2 9
3 1 21 B 1 7
4 1 21 B 2 6
5 2 26 A 1 7
6 2 26 A 2 11Let’s walk through the creation of this plot step by step.
First of all, we need to create the summary data used for the plot.
We need the mean rating per condition per time which determines the heights of the bars.
For the error bars, we need to calculate the standard error according to the formula:
\[SE = \frac{\sigma}{\sqrt{n}}\]
where \(\sigma\) is the standard deviation and \(n\) is the number of observations per each combination of condition and time.
To do this, we can use the tidyverse functions group_by() and describe() introduce earlier:
plot_data <- df_long %>% group_by(condition, time) %>%
summarise(mean_rating = mean(rating),
se = sd(rating)/sqrt(n())) # n() - function that counts number of cases
plot_data
# A tibble: 4 x 4
# Groups: condition [2]
condition time mean_rating se
<fct> <int> <dbl> <dbl>
1 A 1 6.5 0.190
2 A 2 8.23 0.218
3 B 1 7.13 0.150
4 B 2 6.13 0.310Currently the time column of plot_data is a numeric variable.
Let’s change it to factor:
plot_data$time <- factor(plot_data$time)
OK, that’s the preparation done.
Let’s start building our plot, saving it into an object called p.
The lowest layer will define the variables we’re plotting and specify grouping by condition:
As you can see, this layer prepares the groundwork for the plot.
The fill = argument is used to tell ggplot() that we want the bars to be filled using different colour by condition.
Lets add the first plotting layer containing the bars and see what happens:
p + geom_bar(stat = "identity")
Cool, we have ourselves a stacked bar chart.
The stat = argument tells R what statistical transformation to perform on the data.
If we were working with raw data, we could use the mean, for example.
But since our plot_data data frame contains the means we want to plot, we need to tell R to plot these values (“identity”).
We also want the bars to be side by side rather than stacked atop one another.
To do that, we specify the position = argument to the value "dodge2".
This will put them side by side but, as opposed to “dodge” will put a small gap between the unstacked bars (it just looks a bit nicer that way):
p + geom_bar(stat = "identity", position = "dodge2")
One thing that is not very pleasing about this plot that has to be dealt with in the geom_bar() function is the outlines of the bars.
Let’s get rid of them by setting color to NA.
We can now also add this layer to our p plot permanently by reassigning p the value of p plus the layer:
p <- p + geom_bar(stat = "identity", position = "dodge2", color = NA)
p
Nice!
Now to add the error bars, we need to provide new aesthetics to the geom_errorbar layer, namely ymin and ymax defining the lower and upper edges of the bars respectively.
The lower bound of the bars should be the mean \(-\) standard deviation and the upper bound mean + standard deviation:
p + geom_errorbar(aes(ymin = mean_rating - se, ymax = mean_rating + se))
Not quite perfect…
The 4 error bars are drawn in 2 positions rather than in the middle of each corresponding bar.
To get them in the right place, we need to specify the position = argument using the position_dodge2() function.
The difference between "dodge2" and position_dodge2() is that the former is only a shorthand for the latter and it doesn’t allow us to change the default settings of the function.
However, we don’t just want to put the error bars in the right place, we also want them to be a little thinner.
To do that, we can say, that 80% of the space they now occupy should be just padding, thereby shrinking the width of the error bars:
p <- p + geom_errorbar(aes(ymin = mean_rating - se, ymax = mean_rating + se),
position = position_dodge2(padding = .8))
p
Much better. In fact, this is all the hard work done, the rest is just cosmetics. For instance, we can change the axis labels to make them look better:
p <- p + labs(x = "Time", y = "Rating")
p
Next, we can manually change the colours and the title of the legend like this:
p <- p + scale_fill_manual(values = c("grey30", "orangered"), name = "Condition")
p
And finally, we can give the plot a bit more of a classic look using theme_classic() (other themes are available and you can even create your own):
p <- p + theme_classic()
p
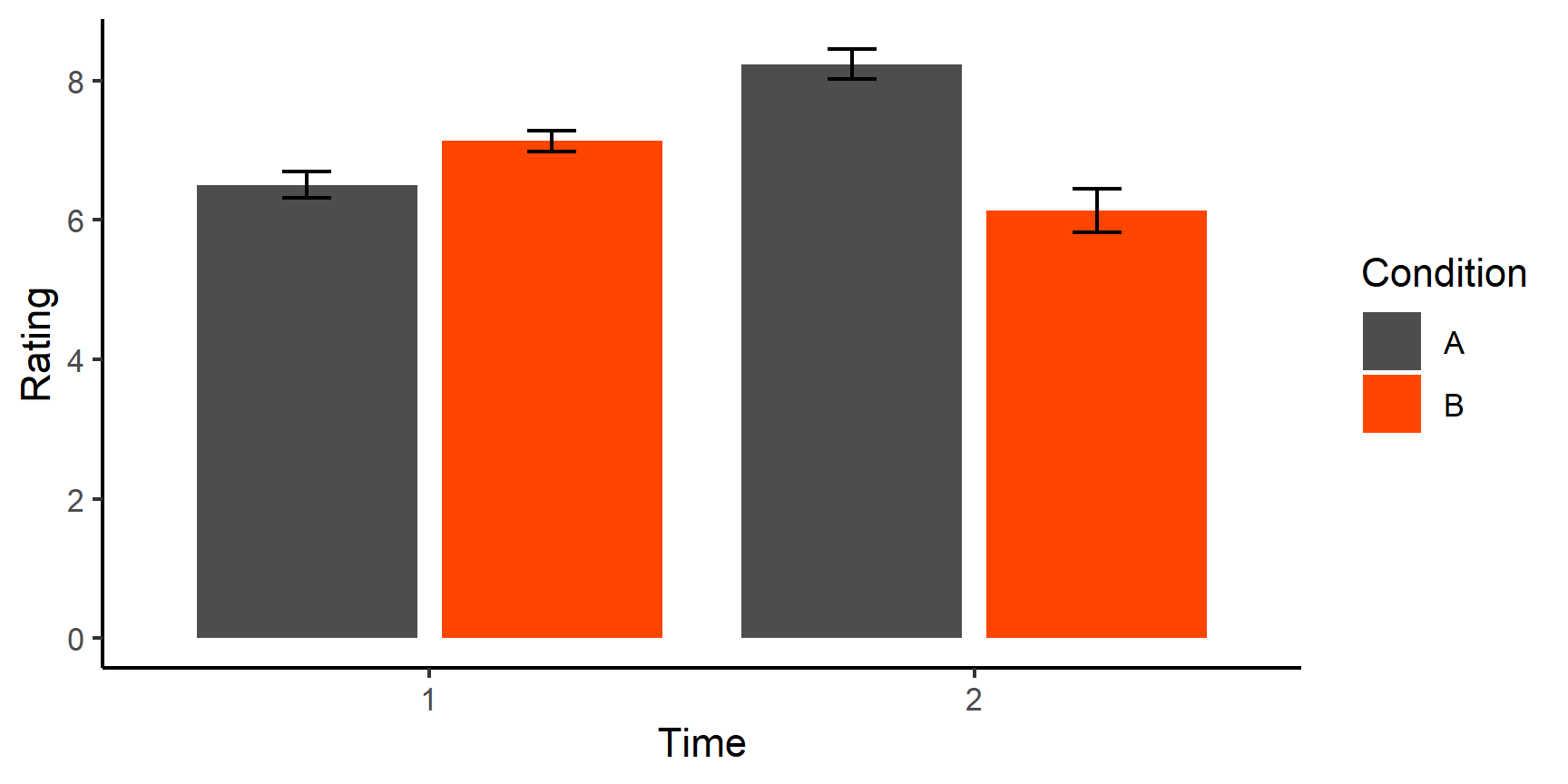
If we now want to, we can export the plot as a .png file using the ggsave() function.
ggsave("pretty_plot.png", p)
Because ggplot2 is designed to work well with the rest of tidyverse, we can create the whole plot including the data for it in a single long pipeline starting with df_long (or even my_data, if you want):
df_long %>%
group_by(condition, time) %>%
summarise(mean_rating = mean(rating),
se = sd(rating)/sqrt(n())) %>%
mutate(time = as.factor(time)) %>%
ggplot(aes(x = time, y = mean_rating, fill = condition)) +
geom_bar(stat = "identity", position = "dodge2", color = NA) +
geom_errorbar(aes(ymin = mean_rating - se, ymax = mean_rating + se),
position = position_dodge2(padding = .8)) +
labs(x = "Time", y = "Rating") +
scale_fill_manual(values = c("grey30", "orangered"), name = "Condition") +
theme_classic()
An interesting thing to point out about ggplot() is that the layers are literally built one on top of another and they are not transparent.
So, if you want the error bars to be sticking out of the columns without the lower halves of the bars visible, you can first build the geom_errorbar() layer and put the geom_bar() layer on top of it:
plot_data %>%
ggplot(aes(x = time, y = mean_rating, fill = condition)) +
geom_errorbar(aes(ymin = mean_rating - se, ymax = mean_rating + se),
position = position_dodge2(padding = .8)) +
geom_bar(stat = "identity", position = "dodge2", color = NA) +
labs(x = "Time", y = "Rating") +
scale_fill_manual(values = c("grey30", "orangered"), name = "Condition") +
theme_classic()
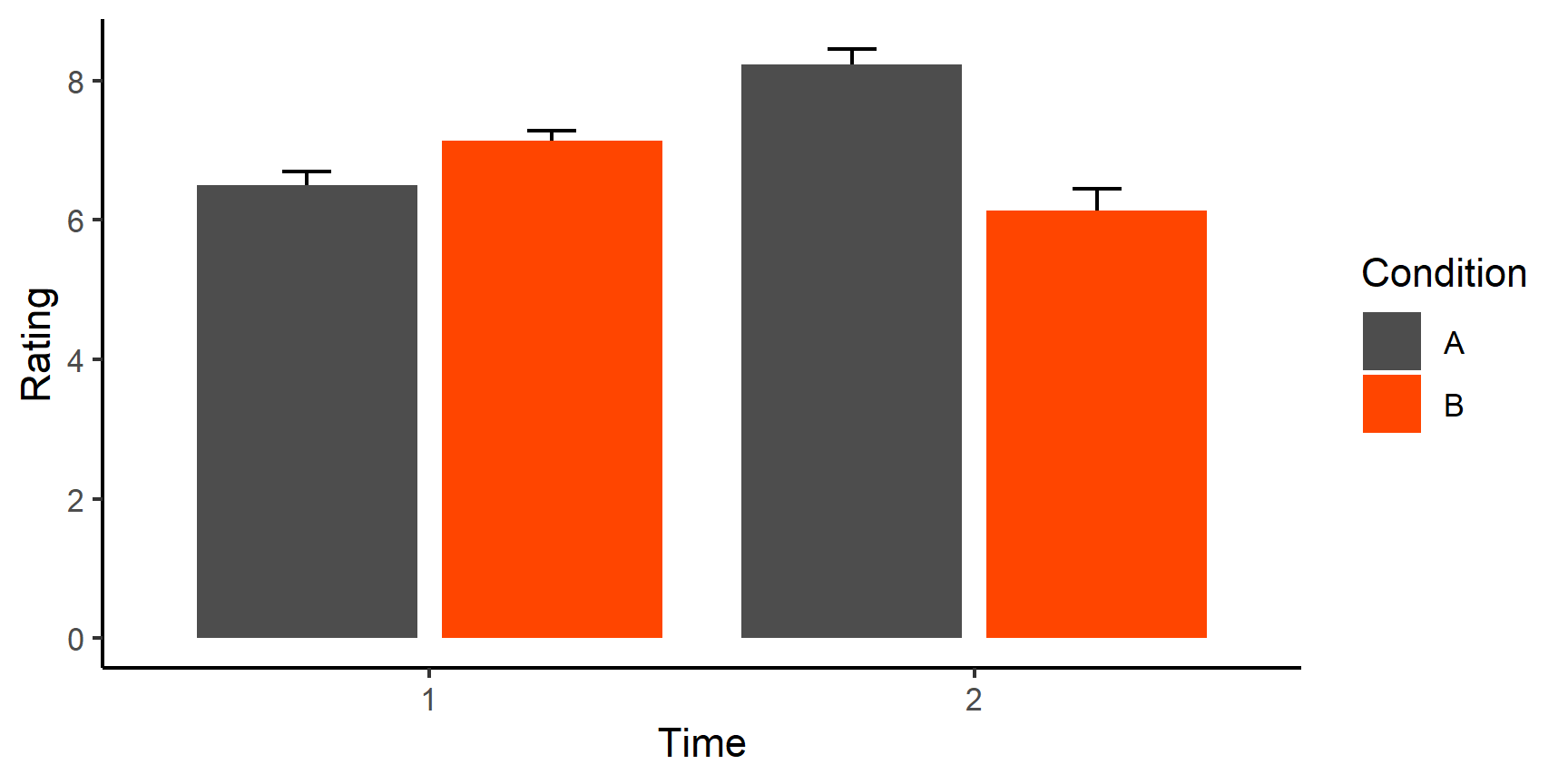
The logic behind building ggplot() graphs should now start making sense.
Admittedly, it takes a little practice and a lot of online resources to feel reasonably confident with the package but once you get there, you will be able to create really pretty plots of arbitrary level of complexity.
A good resource to refer to is the ggplot2 website, where you can find all the other geoms we don’t have the space to cover along with examples.
Useful tips
Following the principles detailed above is guaranteed to make you a better programmer so we hope you will stick to them. To help you along the way just that tiny bit more, here are a few additional tips.
Break it down
Maybe you find yourself struggling with a task and turn to StackOverflow for help. Maybe you manage to find a ready-made answer to your problem or maybe some helpful soul writes one just for you. And maybe it works but you don’t quite understand why.
These things happen and sometimes a line of code can appear quite obscure. Take for example:
When faced with a bit of code like this, it is generally a good idea to try to reverse-engineer it. Let’s give it a go.
First, we can see that this is a for loop that repeats itself 10 times: it starts by assigning the value of 1 to the iterator object i, then executes the code, increments i by 1 and repeats until i == 10.
So to look what the code inside the loop does, we need to set i to some value (1 is a reasonable choice).
i <- 1
Now, let’s start by running the code from the innermost command outwards:
paste0("df_", i, " <- as.data.frame(matrix(rnorm(100 * ", i ,", 0, ", i, "), ncol = i))")
[1] "df_1 <- as.data.frame(matrix(rnorm(100 * 1, 0, 1), ncol = i))"Right, so the first command created a character string that looks like a command. Let’s break it down even further:
rnorm(100 * 1, 0, 1)
[1] 0.060921227 -0.823491629 1.829730485 -1.429916216 0.254137143
[6] -2.939773695 0.002415809 0.509665571 -1.084720001 0.704832977
[11] 0.330976350 0.976327473 -0.843339880 -0.970579905 -1.771531349
[16] -0.322470342 -1.338800742 0.688156028 0.071280652 2.189752359
[21] -1.157707599 1.181688064 -0.527368362 -1.456628011 0.572967370
[26] -1.433377705 -1.055185019 -0.733111877 0.210907264 -0.998920727
[31] 1.077850323 -1.198974383 0.216637035 0.143087030 -1.065750091
[36] -0.428623411 -0.656179477 0.959394327 1.556052636 -1.040796434
[41] 0.930572409 -0.075445931 -1.967195349 -0.755903643 0.461149161
[46] 0.145106631 -2.442311321 0.580318685 0.655051998 -0.304508837
[51] -0.707568233 1.971572014 -0.089998681 -0.014017252 -1.123456937
[56] -1.344130123 -1.523155771 -0.421968210 1.360924464 1.753794845
[61] 1.568364734 1.296755570 -0.237596251 -1.224150136 -0.327812680
[66] -2.412450276 -0.313792873 1.659878705 0.130953101 1.095888683
[71] 0.489340957 -0.778910295 1.743559353 -0.078387285 -0.975553793
[76] 0.070659825 -1.518599529 0.863779033 0.501568385 -0.354781330
[81] -0.488428888 0.936293947 -1.062408386 -0.983820872 0.424247877
[86] -0.451313481 0.925084797 -0.198620810 1.194851017 0.495544705
[91] -2.245152574 -1.335371360 1.282775206 0.690795904 -0.967062668
[96] -1.345793685 1.033665389 -0.811776460 1.801725479 1.771541960OK, this is easy. The first bit generates \(100 \times i\) random numbers with a mean of zero and a standard deviation of i. Let’s move one layer out:
[,1]
[1,] -1.45469137
[2,] -0.84565431
[3,] -1.25047966
[4,] 0.66728807
[5,] -1.29076969
[6,] -2.03500354
[7,] 2.02134699
[8,] 1.00597349
[9,] 0.81712360
[10,] -0.66398828
[ reached getOption("max.print") -- omitted 90 rows ]This command put those numbers into a matrix with 100 rows and i columns.
Next:
df_1 <- as.data.frame(matrix(rnorm(100 * 1, 0, 1), ncol = i))
This line converts the matrix into a data.frame and stored it in an object called “df_i”.
Remember, i takes values of 1-10, increasingly each time the loop is repeated.
All good thus far but why is the command a character string (in “quotes”)
What is that good for?
Well, turns out that the parse() function can take a string with a valid R code inside and turn it to an expression:
This expression can be then evaluated using the eval() function:
eval(parse(text = paste0(
"df_", i, " <- as.data.frame(matrix(rnorm(100 * ", i , ", 0, ", i, "), ncol = i))")))
# printout truncated
df_1
V1
1 1.1936917
2 -0.1163955
3 0.5248586
4 0.2144215
5 -0.1344495
6 0.1685091
7 0.9647328
8 0.4087789
9 -0.4664382
10 -2.2397830
[ reached 'max' / getOption("max.print") -- omitted 90 rows ]So what the entire loop does is create 10 data frames named df_1 to df_10, each containing 100 rows and a different number of columns (1 for df_1, 6 for df_6 etc.) with random numbers.
Moreover, each data.frame contains random numbers with different standard deviations.
And so, just like that, with a single line of code we can create 10 (or more!) different R objects with different properties.
Cool, isn’t it?
Hope this example demonstrates how, using systematic reverse-engineering, you can come to understand even a daunting-looking code with functions you haven’t seen before.
Handy functions that return logicals
Finally, here are some useful functions with which you might want to familiarise yourself. They will make cleaning your data much easier.
==, takes avector,matrix, or adata.frameand compares every element thereof to a single value. Returns alogical vectorwithTRUEfor elements that are equal to the compared value andFALSEotherwise. ComparingNAreturnsNA.<, same as==, butTRUEis returned if element is less than the compared value.>, same as==, butTRUEis returned if element is greater than the compared value.<=, same as==, butTRUEis returned if element is less than or equal to the compared value. In other words, it is a negation of (complementary operation to)>.>=, same as==, butTRUEis returned if element is greater than or equal to the compared value. Negation of<.%in%, same as==, but can take avectoron the right hand side. Each element of thevector/matrix/data.frameto the left is compared to each element of the vector to the right. For example:- all functions that begin with ‘
is’, e.g.:is.na(), takes avector,matrix, or adata.frameand returns alogical vectorwithTRUEif given element is anNAandFALSEotherwise.is.numeric(), takes any object and returnsTRUEif it is a numeric vector andFALSEotherwise.is.factor(),is.matrix(),is.data.frame(),is.list(), same asis.numeric()but returnTRUEif the object provided is afactor,matrix,data.frame, orlist, respectively.isTRUE(), returns a singleTRUEif the expression provided evaluates toTRUEand a singleFALSEotherwise. OnlyisTRUE(TRUE)returnsTRUE.isTRUE(FALSE),isTRUE(c(TRUE, TRUE))and anything else returnsFALSE. Works withNAs so can be useful for combining with logical operators that returnNAwhen comparing missing values.
any(), takes a logical vector and returnsTRUEif any of its elements equalsTRUE, andFALSEotherwise, e.g.,any(1:5> 4)returnsTRUE.all(), likeany()but returnsTRUEonly if all of the elements of the vector provided areTRUE.all.equal(), takes two objects and returnsTRUEif they are identical and a vector of all discrepancies otherwise. Sensitive to attributes soall.equal(1:5, factor(1:5))does not returnTRUE. Good to use along withisTRUE()!all.equal(df, df)[1] TRUEall.equal(df, my_list)[1] "Names: 3 string mismatches" [2] "Attributes: < names for target but not for current >" [3] "Attributes: < Length mismatch: comparison on first 0 components >" [4] "Length mismatch: comparison on first 3 components" [5] "Component 1: 'current' is not a factor" [6] "Component 2: Modes: numeric, character" [7] "Component 2: Lengths: 10, 5" [8] "Component 2: target is numeric, current is character" [9] "Component 3: Modes: numeric, list" [10] "Component 3: Lengths: 10, 2" [ reached getOption("max.print") -- omitted 3 entries ][1] FALSE&, “AND” takes two Booleans and returnsTRUEif both of them areTRUE,NAif either isNA, andFALSEotherwise. Can be applied over twological vectorsof the same length:|, “OR” is the same as&but returnsTRUEif either or both of the two compared elements isTRUE.xor(), “exclusive OR” is same as above but returnsTRUEonly if either the first or the second, but not both of the two compared elements, isTRUE.&&and||, single-element versions of&and|. They only compare the first element of both of the vectors provided (i.e., x[1] vs y[1]):- all of the above can be negated using the ‘
!’ operator, e.g.:x != y!x > y!is.na(x)!any(is.na(x))is equivalent toall(!is.na(x))!(x & y)is equivalent toxor(x, y) | (!x & !y)
Jargon dictionary
Argument. Parameter that determines the behaviour of a function.
Can be optional or required.
E.g., in rnorm(n = 100, mean = 40, sd = 5), n, mean, and sd, are all arguments of the rnorm function.
Character. One of four vector classes (along with numeric, logical, and factor).
Vector of this class contains quoted ("") alphanumeric elements. Maths cannot be calculated with character vectors.
Class. Basic property of an object, e.g., numeric, character, list, data.frame, function.
Command. Combination of functions, objects, and arguments that, if grammatically and syntactically correct, serves as an instruction for the computer to perform an operation.
Console. Direct interface to the R interpreter. This is where commands get run and where output of operations is printed.
Data frame. Primary way of storing data sets. Square arrangement of elements where a single column can only contain elements of the same class. Sits between lists and matrices and can be subsetted using $column_name, [[column index or name]] or [row, column].
Data structure. Grouping of elements, e.g., vector, matrix, list.
Element. Constituent part of data structures (vectors, lists, data.frames…).
Factor. One of four vector classes (along with numeric, logical, and factor). Factors are used mainly for plotting and modelling nominal and ordinal variables. They are essentially integer variables with character labels superimposed on them.
Function. A chunk of code that takes some input values and based on them returns some object. Functions are always used with () after function name.
Logical. One of four vector classes (along with numeric, logical, and factor). Logical vectors only contain Boolean elements TRUE and FALSE.
List. A one-dimensional data structure that can contain as its elements any data structures (including lists, data.frames…) of any length and any class. Elements can be named and can be subsetted either using the $ notation or [[]].
Matrix. A square arrangement of elements of a single class. Has 2 dimensions: rows and columns. Can be subsetted using [rows, columns].
Numeric. One of four vector classes (along with numeric, logical, and factor).
Object. Anything in R. :-) Contents of an object can be printed/accessed by calling its unquoted name (i.e., with no ""s).
Operator. A function in infix form, such as +, <-, %in%, or %>%.
Output. Object returned bu a function.
Print. To output the content of an object into the console.
Script. A text file including a sequence of commands written in order to achieve some goal, e.g., data processing/analysis. It should be written in a way that allows it to be evaluated (run) line by line without errors.
String. Element of a character vector, such as "A", "test_score_1", or "&*$£(*)". Always surrounded by quotes. Strings are not interpreted by R: "mean" does not do anything, it is just a string, not the mean() function.
Variable. Colloquial term for either a vector or a column of a data frame.
Vector. Most basic data structure. One-dimensional arrangement of elements of the same class. Only has length and can be subsetted using [].
An important insight immortalised by Newton Crosby in the 1986 cult movie Short Circuit: “It’s a machine, Schroeder. It doesn’t get pissed off. It doesn’t get happy, it doesn’t get sad, it doesn’t laugh at your jokes. It just runs programs.”↩︎
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.↩︎